
Wie bereits beschrieben, stellte sich das Tool cAdvisor zum Erstellen von Metriken von Docker-Containern als nicht sinnvoll nutzbar heraus. Für Prometheus als Shooting-Star unter den Monitoring-Anwendungen gibt es jedoch nicht nur Exporter, d.h. spezielle Tools, die dafür zuständig sind, von der jeweiligen zu überwachenden Anwendung bzw. dem entsprechenden System Daten zu sammeln und in einem von Prometheus direkt nutzbaren Format zur Verfügung zu stellen, sondern mittlerweile werden diese Metriken von nicht wenigen Anwendungen direkt angeboten. Da es kaum sinnvoll ist, diese immer größer werdende Liste hier anzugeben, verweise ich an dieser Stelle auf die Seite „Exporters and Integrations“ in der Dokumentation von Prometheus. Wie aufgrund des Titels leicht zu erraten ist, reiht sich auch Traefik in die Riege der Software mit nativer Unterstützung von Prometheus ein.
Native Prometheus-Metriken von Traefik
Tatsächlich habe ich nur wenig darüber gefunden, wie sich diese Eigenschaft von Traefik nutzen lässt, auch die entsprechende Dokumentation von Traefik spart aktuell mit Beispielen. Aus diesem Grund beschreibt der folgende Artikel mein Vorgehen bzw. meine Erfahrungen und stellt ein funktionsfähiges Beispiel vor. Ich werde jedoch nicht auf die Installation von Prometheus und Grafana eingehen, da es dazu bereits Unmengen von Artikeln oder Blog-Beiträgen gibt, ganz zu schweigen von umfassender offizieller Dokumentation. Das folgende Beispiel setzt somit eine lauffähige und aktuelle Version von Prometheus voraus, ebenso sollte für das Betrachten bzw. Erstellen von Dashboards, somit zur Aufbereitung der Metriken eine Grafana-Installation vorhanden sein, die auf die zu verwendende Prometheus-Instanz als Datenquelle zugreifen kann.
Monitoring-Infrastruktur mit Prometheus und Grafana
Bei den ersten Überlegungen zum Aufbau des Monitoring-Systems stellte sich mir die Frage, auf welchem Server Prometheus und Grafana am besten zu platzieren seien. Wie bereits des Öfteren erwähnt, nutze ich einige VMs bei momentan zwei unterschiedlichen Providern bzw. Cloud-Anbietern. Und das Monitoring-System sollte gerade diese VMs und deren Dienste überwachen, um etwa bei Ausfall Alarm zu schlagen, daher wäre es eher kontraproduktiv gewesen, Prometheus auf einer der VMs zu installieren. Eine weitere VM allein für das Monitoring hinzu buchen, erschien mir jedoch ebenfalls nicht sinnvoll bzw. nicht kosteneffizient. Demgegenüber waren ausreichend Ressourcen in der internen bzw. heimischen Infrastruktur vorhanden, weshalb ich eine VM für Prometheus und Grafana eingerichtet habe. Da die Metrics-Daten natürlich nicht für alle Öffentlichkeit lesbar sein sollten, musste dafür gesorgt werden, dass einerseits der Zugriff verschlüsselt erfolgt und andererseits eine Authentifizierung stattfindet. Dafür eignet sich Traefik natürlich wunderbar, die Konfiguration ist letztlich ähnlich aufgebaut wie für den Zugriff auf die Traefik-Dashboards.
Das Ziel – mit kleinen Abweichungen vom Standard
Das Ziel bestand somit darin, die Metriken von Traefik bereitzustellen, jedoch nur nach Authentifizierung mittels HTTP-Basic-Authentication, verschlüsselt auf dem Standard-Port für https, und unter einem individuellen Pfad. Letzteres wäre zwar optional gewesen, aber da auf dem Standard-Pfad „/metrics“ bereits die Metriken des Monitoring des Systems von node_exporter vorhanden waren, erschien mir die Verwendung eines anderen Pfades für sinnvoll. Der laut Dokumentation für den Metrics-Endpoint standardmäßig genutzte Port wäre 8082, doch warum einen extra Port für die Metriken nutzen, wenn der Standard-https-Port bereits existiert? Dieses Szenario mag nicht typisch sein, die Anforderungen in größeren oder internen Netzwerken sind natürlich ganz andere, und dankenswerterweise kann Traefik so individuell konfiguriert werden, dass allen gerecht wird.
Tatsächlich reicht zur Nutzung der Standard-Einstellungen des Traefik-internen Metrics-System der Command-Parameter „--metrics.prometheus=true„, bei Verwendung von TOML- oder YAML-Files zur Konfiguration finden sich die entsprechenden Pendants in der Traefik-Dokumentation. In dem Fall wird Traefik den Endpoint bzw. Pfad „/metrics“ zur Verfügung stellen, und zwar auf dem Hostnamen, auf dem das Traefik-Dashboard verfügbar ist. Der Schlüssel zur Anpassung liegt in der Option „--metrics.prometheus.manualrouting=true„. Damit kann der interne Service namens „prometheus@internal“ von einem eigenen Router verwendet werden, Middlewares können hinzugefügt werden etc., analog zur Nutzung des ebenfalls internen Services „api@internal“ des Traefik-eigenen Dashboards.
Einrichtung der Traefik-Metriken
Die folgende Konfiguration ist somit eine Ergänzung des im Artikel „Eine kleine Traefik-Geschichte“ vorgestellten Docker-Compose-Files, mit dem der Traefik-Service eingerichtet wird. Zunächst werden die Prometheus-Metriken aktiviert und die Nutzung eines eigenen Routers ermöglicht:
version: '3.3'
services:
traefik:
image: traefik:v2.3
[...]
command:
- "--providers.docker"
[...]
- "--metrics.prometheus=true"
- "--metrics.prometheus.manualrouting=true"
Der Router wird ebenfalls in dem Docker-Compose-File definiert, dazu werden diese Zeilen im Bereich Labels hinzugefügt:
labels: # Enable Traefik for this service, to make it available in the public network - "traefik.enable=true" [...] # custom path for prometheus metrics - "traefik.http.middlewares.admin-auth-metrics.basicauth.users=USERNAME:PASSWORD" - "traefik.http.routers.traefik-public-metrics-http.rule=Host(`traefik1.xyzcdn.xyz`) && PathPrefix(`/traefik-metrics`)" - "traefik.http.routers.traefik-public-metrics-http.entrypoints=http" - "traefik.http.routers.traefik-public-metrics-http.middlewares=https-redirect" - "traefik.http.routers.traefik-public-metrics-https.middlewares=secHeaders@file" - "traefik.http.routers.traefik-public-metrics-https.rule=Host(`traefik1.xyzcdn.xyz`) && PathPrefix(`/traefik-metrics`)" - "traefik.http.routers.traefik-public-metrics-https.entrypoints=https" - "traefik.http.routers.traefik-public-metrics-https.tls=true" - "traefik.http.routers.traefik-public-metrics-https.service=prometheus@internal" - "traefik.http.routers.traefik-public-metrics-https.tls.certresolver=le-tls" - "traefik.http.routers.traefik-public-metrics-https.middlewares=secHeaders@file,admin-auth-metrics,def-compress"
Über die Namen für Router, Middleware etc. kann man natürlich trefflich diskutieren, ich habe hier einfach die bestehenden Namen mit „-metrics“ ergänzt, um eine eineindeutige Zuordnung zu ermöglichen.
Zunächst wird eine Middleware für die HTTP-Basic-Authentication definiert, die Generierung des Passwortes folgt dem bereits bekannten Schema. Der Pfad für den Aufruf der Metriken soll „/traefic-metrics“ lauten, die Definition erfolgt mit der PathPrefix-Option. Der Redirect von http zu https, die Nutzung von TLS per Let’s Encrypt, das Hinzufügen der Middlewares zum Router etc. wurden bereits beschrieben. Tatsächlich sind diese Komponenten völlig analog zum Dashboard eingerichtet, nur dass hier der Service „prometheus@internal“ verwendet wird.
Die Definition einer eigenen Middleware („admin-auth-metrics„) für die Authentifizierung ermöglicht die Nutzung einer anderen Username-Passwort-Kombination als für den Zugriff auf das Traefik-Dashboard.
Wird Traefik nun neu gestartet, sollten in der UI des Dashboards die die neuen Komponenten, also Router, Middleware und Service sichtbar sein. Ein Request auf den Pfad „/traefik-metrics“ sollte nach Eingabe der Zugriffsdaten zu den Metriken führen.
Achtung – das Traefik-Dashboard sollte zuvor geschlossen werden! Denn falls es im selben Browser, aber einem anderen Tab geöffnet bleibt, kommen die Nachteile von HTTP-Basic-Authentication zum Tragen. Das Dashboard stellt regelmäßig Anfragen an das Backend, authentifiziert sich dabei, überschreibt damit die Zugangsdaten für die Metriken, weshalb es so wirkt, als wären diese ungültig. Insgesamt ein ziemliches Chaos, doch dieses Verhalten ist in der Praxis irrelevant, da Prometheus nur die URL der Metriken mit den entsprechenden Zugangsdaten nutzt, für den Zugriff auf das Dashboard besteht überhaupt kein Anlass. Und umgekehrt – man wird die Metriken in Rohform wohl nie mittels Browser auslesen wollen, es sei denn für einen ersten Test.
Prometheus, übernehmen Sie!
Zu guter Letzt muss Prometheus noch von den Traefik-Metrics erfahren. Das geschieht im Bereich „scrape-configs:“ der Prometheus-Konfiguration, meist in der Datei „prometheus.yml“ vorliegend. Für das o.g. Beispiel würde die Konfiguration wie folgt aussehen:
scrape_configs:
- job_name: stralsund_traefik
scrape_interval: 5s
scheme: https
metrics_path: '/traefik-metrics'
static_configs:
- targets:
- traefik1.xyzcdn.xyz:443
basic_auth:
username: USERNAME
password: 'SUPERDUPERPASSWORT'
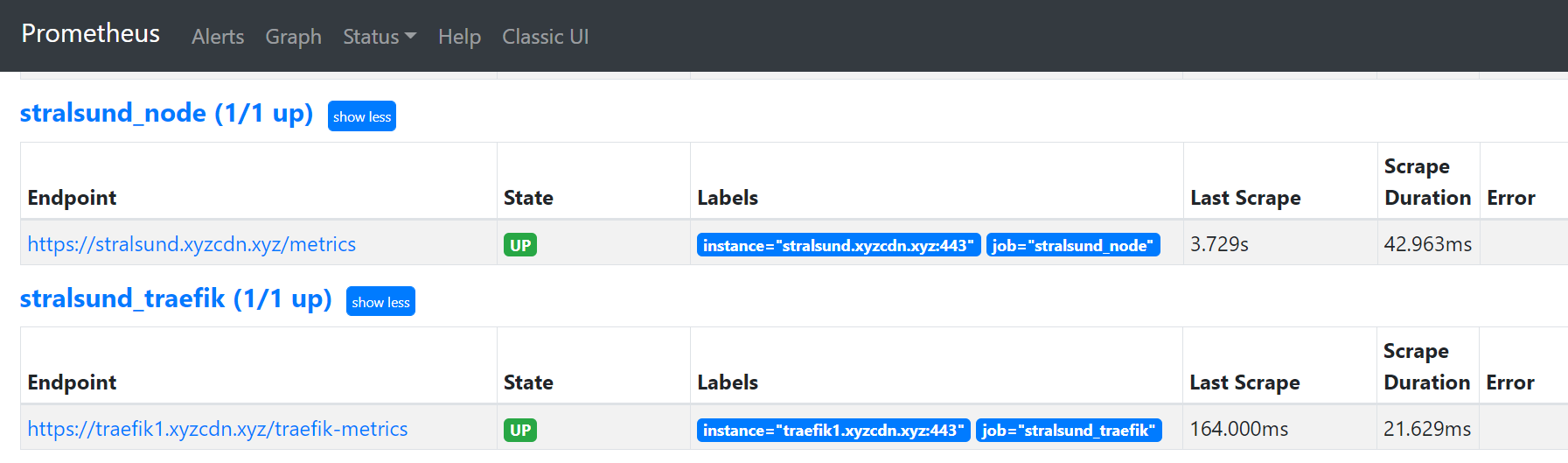
Nach einem Restart von Prometheus sollte in der Prometheus-UI im Bereich Status -> Targets der neue Jobname auftauchen, der Status müsste „up“ anzeigen.
Damit stehen die gesammelten Metriken auch in Grafana zur Verfügung und können in einem passenden Dashboard angezeigt werden. Dazu bietet Grafana auf seiner Website eine Unmenge an Vorlagen, die entweder direkt genutzt werden können oder zumindest bei der Erstellung eigener Dashboards helfen können. Im Gegensatz zum wirklich hervorragenden und umfassenden „Prometheus Node Exporter Full„-Dashboard bin ich bei den zur Verfügung stehenden Dashboards für die Traefik-Metriken bislang etwas ernüchtert. Bislang habe ich zwar nur zwei getestet, aber so richtig gefällt mir momentan keines davon. Somit werde ich hier weiter auf die Suche gehen müssen – oder gar ein eigenes erstellen. Dazu muss ich allerdings erwähnen, dass ich mich zum Zeitpunkt des Schreibens dieses Artikels erst seit einigen Tagen mit dem gesamten Komplex Monitoring mit Prometheus, den diversen Exportern, sowie Grafana bzw. dessen Dashboards beschäftigt habe. Insofern habe ich bis dato nur ein wenig an der Oberfläche gekratzt – so zumindest mein Eindruck, und meine Erfahrungen sind bislang sehr begrenzt. Eine Empfehlung für ein adäquates Dashboard für die Traefik-Metriken kann ich insofern aktuell nicht geben.
Die Krux mit Grafana-Dashboards
Die Grafana-Dashboards „Traefik 2“ und „Traefik 2.2“ zeigen jedenfalls ein Bild, in dem nicht in Bezug auf die in der Prometheus-Konfigurationsdatei vorhandenen Jobs unterschieden wird. Insofern ist die Darstellung gelinde gesagt völlig unbrauchbar.
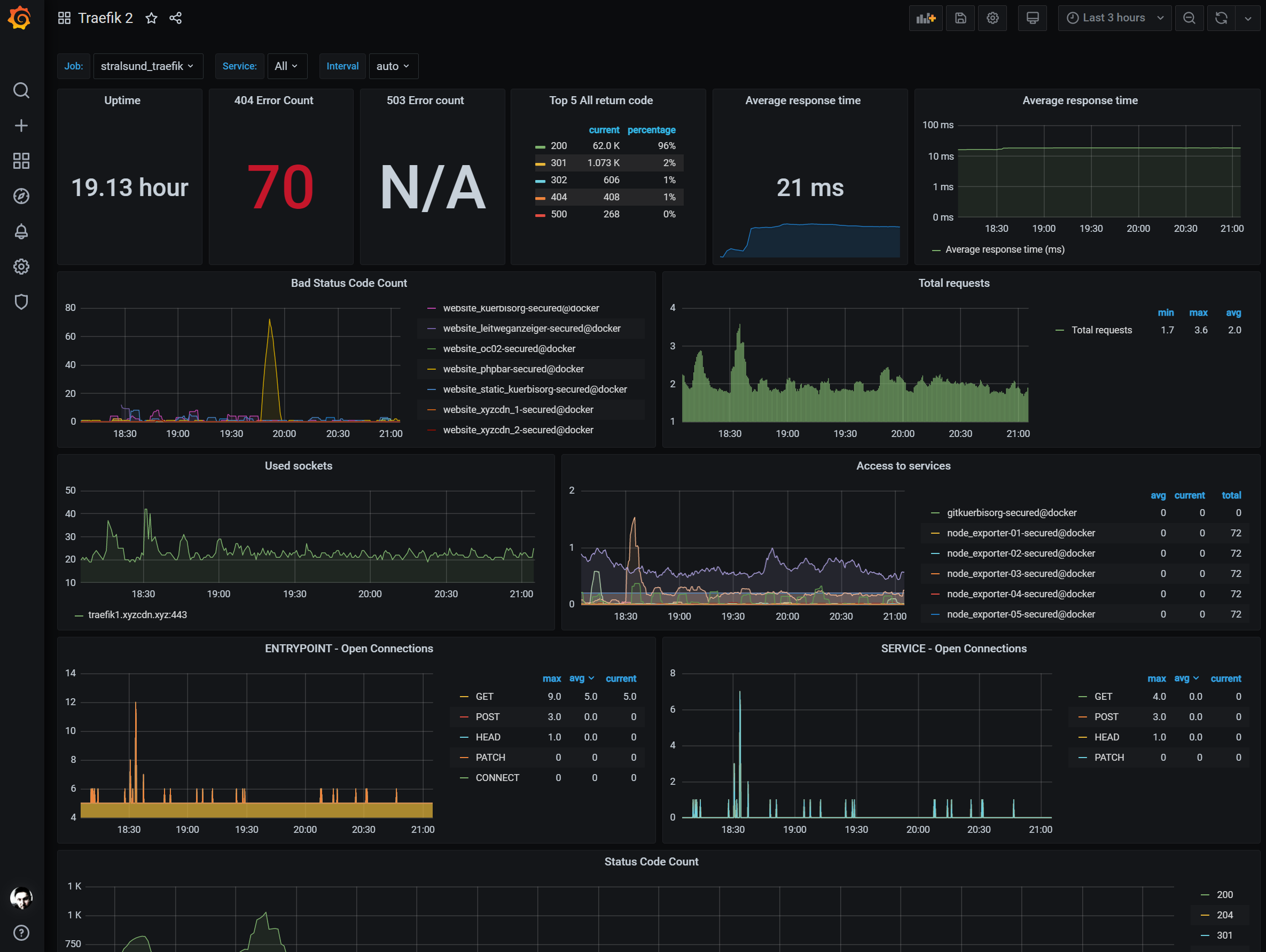
Aber es wäre ja auch langweilig, wenn alles gleich beim ersten Mal perfekt wäre, oder?
Das könnte auch interessant sein:



Super, hervorragend und detailliert erklärt. Vielen Dank!