
Nach der Entscheidung für einen Anbieter von „Cloud-Storage“ folgt der nächste Schritt – die Umsetzung des Backup-Konzeptes, das ich mir inzwischen skizziert hatte. Grundsätzlich basiert es auf einer Struktur mit mehreren Stufen. Hinzu kommen unterschiedliche Backup-Medien zur Aufnahme der Daten, dies wiederum in Abhängigkeit von der Art der zu sichernden Daten.
Die Infrastruktur besteht aus mehreren Komponenten. Zum Überblick siehe folgende Skizze:
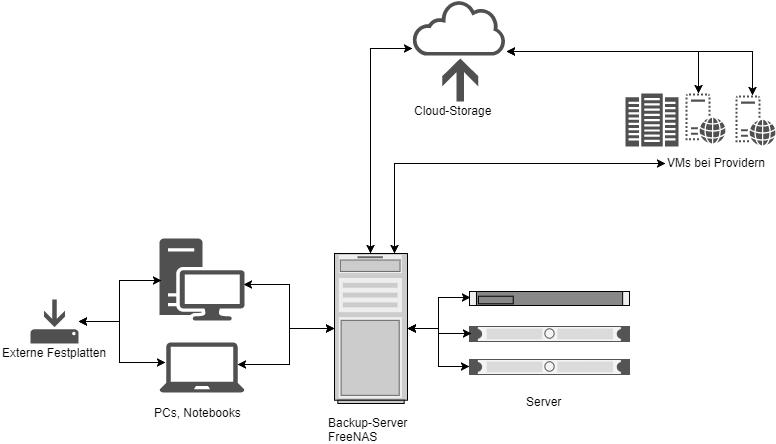
Backup-Quellen und -Arten
In meinem Szenario sind mehrere Backup-Quellen vorhanden. Zum einen gibt es die klassischen Arbeitsplatz-Rechner, also PC und Notebook. Zum anderen sind noch Server abzusichern bzw. die Daten auf den darauf befindlichen VMs.
Als dritte Quelle habe ich bei Providern ein paar kleinere VMs gebucht, die ebenfalls gesichert werden müssen, wiederum in Abhängigkeit der Anwendungen, die darauf betrieben werden.
Sehen wir uns die jeweiligen Komponenten genauer an.
PCs und Notebooks
Die Arbeitsplatz-Rechner sind letztlich gefährdet durch Trojaner, Sicherheitslücken & Co., außerdem würde eine Wiederherstellung inkl. Download diverser Programme, Installation etc., sehr lange dauern. Daher bestand das Ziel in einem möglichst umfassenden Backup. Im besten Fall sollte bei einem etwaigen Ausfall die vorherige Umgebung aus einem Abbild (Image) wiederherstellbar sein. Dies betrifft zunächst das Betriebssystem an sich, in meinem Fall tatsächlich Windows 10, während die Daten auf der zweiten, d.h. Daten-Partition zwar gesichert sein sollen, aber hierbei genügt eine Kopie der reinen Nutz-Daten, so wäre etwa ein Backup des meist recht umfangreichen Download-Ordners überflüssig. Ausnahmen bestätigen die Regel, also falls sich im Download-Ordner Dateien befinden sollten, die sich nicht einfach durch erneuten Download wiederherstellen lassen, oder falls dieser Vorgang subjektiv zu lange dauern sollte, empfiehlt sich hingegen ein Backup – vielleicht empfiehlt sich dabei aber einfach die Verwendung eines weiteren Ordners, in dem wichtige Downloads landen, während der „normale“ Download-Ordner getrost seinem Schicksal überlasen werden kann.
Somit bestanden die Anforderungen darin, ein Image vom Betriebssystem, installierten Programmen etc., erstellen zu können, von dem auf einfache Art und Weise das komplette System wieder hergestellt werden kann, und andererseits die Nutz-Daten datei- bzw. ordner-weise zu sichern.
Server und VMs
Bei den Servern ist es einerseits einfacher, andererseits auch komplexer. – gleichzeitig. Zunächst einmal wäre die Frage zu stellen, was jeweils auf den VMs läuft. Beispielsweise wären das ein interner DNS, eine Redmine-Installation, diverse Entwicklungs- bzw. Test-Server, Datenbanken, Monitoring-Tool usw., alles unter recht aktuellen Ubuntu-Installationen. Ein einfaches Beispiel wäre der interne DNS-Server. Die zu sichernden Daten wären hierbei minimal, letztlich würde ich dabei nicht die komplette VM bzw. das VM-Image sichern, sondern nur die Nutz-Daten, die sich auf einige KB Konfiguration in /etc/bind beschränken. Sämtliche andere Konfiguration wäre einfach wieder herzustellen bzw. würde das bedeuten, dass eine VM eingerichtet werden muss, dann der DNS-Server dahingehend konfiguriert, dass die alten Daten wieder ausgeliefert werden. In meinem heimischen Netzwerk sehr einfach mit ein paar Text-Dateien möglich. Im Firmenumfeld und je nach eingesetzter Server-Software sieht dies wieder anders aus, aber das ist auch ein anderes Szenario.
Ein komplexerer Fall wäre z.B. Redmine. Die Installation befindet sich ebenfalls auf einer VM, inkl. Datenbank, Web-Server, hochgeladenen Dateien und dem Sourcecode von Redmine. Dazu kommt, dass die Installation recht aufwändig ist. Hierbei wäre abzuwägen – Backup des VM-Images oder Backup der Nutz-Daten? Sollte genug Platz auf dem Backup-Speicher vorhanden sein, würde ich mich für ein Backup des VM-Images aussprechen. Zur Sicherheit vielleicht noch ein Backup der Nutz-Daten, d.h. Datenbank-Dump, Datei-Uploads, Sourcecode inkl. Konfigurationsdateien sowie Konfigurationen der Server-Software (Nginx, Thin).
Alle anderen Systeme liegen irgendwo dazwischen – oder würden vielleicht gar kein Backup benötigen, falls einfach nur ein paar (leicht rekonstruierbare) Test-Daten aus anderen Quellen darauf liegen. Oder auch, falls die Datenmenge zu groß wäre. Aber dann sind wir auch nicht mehr im heimischen Bereich, sondern hätten die Möglichkeit, auf mehrere Data-Center auszuweichen o.ä..
VMs bei Providern
Für die bei Providern betriebenen VMs – für Server wäre das Vorgehen analog – gilt eigentlich dasselbe wie für die internen Server. Nur je nach Backup-Ziel wäre zu untersuchen, wie die Bandbreite der Anbindung an das Backup-Medium ist. Vielfach bieten Provider eigene Backup-Server, oft ist im Mietpreis sogar ein gewisser Backup-Space mit inbegriffen. Die Nutzung dieses Backup-Platzes ist natürlich sinnvoll, sollte aber nicht die einzige Sicherung sein. Was wäre, wenn der Provider angegriffen wird oder ein Stromausfall zur Schädigung der Hardware führt, auf der dann zufällig auch der Backup-Space betrieben wird? Oder wenn – durch welche Umstände auch immer – es zu Problemen bei der Zahlung kommt und der Provider einem den Zugriff verweigert? Und so weiter, Beispiele gibt es viele, sicherlich schadet es nicht, auf Nummer sicher zu gehen.
Backup-Ziele
Wie bereits erwähnt, halte ich ein mehrstufiges Verfahren für sinnvoll. Das erste Backup wird immer auf einem „nahen“ System erstellt. Von dort geht es weiter, d.h. die Daten werden auf ein zweites Medium kopiert. Was heißt das genau?
Backup-Server / FreeNAS
Für die zu sichernden Dateien und Verzeichnisse läuft eine Backup-Server getaufte VM unter FreeNAS im lokalen Netz. Das System bietet einigen Speicherplatz und dient als erste Backup-Instanz für alle Daten der Arbeitsplatz-Rechner und Server.
Für FreeNAS habe ich mich aus mehreren Gründen entschieden. Einerseits wollte ich damit Erfahrungen sammeln. Ok – für einen Backup-Server vielleicht nicht der entscheidende Grund, eher das genaue Gegenteil, aber ich hatte vor einigen Jahren bereits ein FreeNAS-System eingesetzt, es lief stabil und zuverlässig, diese Attribute sind für einen Backup-Server sicherlich nicht schlecht. Zum anderen das Filesystem ZFS bzw. insbesondere die Snapshots der Datenträger bzw. Datasets. Das alles kommt verpackt in einer anständigen GUI. Zwar bietet Linux mit btrfs inzwischen vergleichbare Features, aber leider hat OpenMediaVault noch keine UI dafür – zur Einrichtung müsste man die Kommandozeile bemühen. Nicht, dass das grundsätzlich schlecht oder nicht interessant genug wäre, aber in dem Fall wollte ich den Aufwand möglichst gering halten.
Den zur Verfügung stehenden Speicher habe ich aufgeteilt in Datasets. Die Datasets sind wiederum Usern zugeordnet, bzw. die User haben jeweils ausschließlich Zugriff auf ihr eigenes Dataset. Der Zugriff erfolgt per FTP – das hört sich fast veraltet an, aber wenn der Zugriff per SMB-Share erfolgen würde und am besten noch direkt beim Systemstart als Laufwerk unter Windows automatisch eingebunden werden würde, könnte man sich den Aufwand auch sparen, soll heißen, nicht nur der User, sondern auch die unterwünschten Trojaner könnten darauf zugreifen und die Backup-Dateien löschen, verschlüsseln o.ä.. Bislang gilt FTP für den Zugriff als durchaus sicher, zum einen ist keine dauerhafte Verbindung vorhanden, zum anderen müssten dann erst die Zugangsdaten herausgefunden werden. Das muss nicht dauerhaft so bleiben, es empfiehlt sich auch hier, am Ball zu bleiben und die einschlägigen Security-Meldungen nicht zu verpassen.
Die unter FreeNAS eingerichteten User sind jeweils den zu sichernden Rechnern zugeordnet und heißen z.B. „ubakpc10“ oder „ubakmac“. Dass sich die Passwörter unterscheiden sollten, versteht sich von selbst. Das soll verhindern, dass selbst wenn ein Account kompromittiert wäre, alle anderen ebenfalls in Mitleidenschaft gezogen werden könnten. Somit ist sicher gestellt, dass die Backup-Software jeweils nur Zugang auf ihr eigenes Dataset bzw. das Dataset des zugehörigen Users auf dem Backup-Server hat.
Alle Dienste lassen sich mittels der FreeNAS-GUI verwalten, wenngleich auch nicht immer so intuitiv wie es wünschenswert wäre. Beispielsweise wäre zunächst ein neues Dataset anzulegen, was standardmäßig nur dem root-User Zugriff bietet. Zwar lassen sich die Zugriffsrechte ändern, aber dazu muss der User erst angelegt sein. Also anschließend User anlegen, das Home-Verzeichnis auf das neu angelegte Dataset zeigen lassen und anschließend erneut das Dataset konfigurieren, so dass der soeben angelegte User auch Schreibrechte erhält.
Natürlich wäre auch die Nutzung eines NAS unter OpenMediaVault oder gar eines Komplettsystems bzw. eines NAS-Systems wie Synology o.ä. möglich. Synology bietet sehr gute und ausgereifte Features, etwa das Backup in die Cloud, leider haben die schnelleren Systeme bzw. diejenigen mit der Möglichkeit, vier Festplatten einzubauen, auch einen gewissen Anschaffungswiderstand… Soll heißen, die andere, nun eingesetzte Hardware war da, somit lockte das FreeNAS-Abenteuer mehr.
Externe Festplatten
Ebenfalls als erste Instanz nutze ich externe Festplatten, und zwar an den Arbeitsplatz-Rechnern, möglicherweise auch nur an einem. Das ist noch ein wenig „work-in-progress“, zumindest am primären PC befindet sich eine Platte, auf der die System-Images gespeichert werden. Vermutlich werde ich auf „c’t wimage“ zurück greifen (die ersten Tests waren sehr vielversprechend), so dass laut Empfehlung ein monatliches Backup reichen würde. Dazu sollten mehrere externe Platten vorhanden sein, die ggf. auch außerhalb der eigenen vier Wände gelagert werden sollten.
Da sich auf den eingesetzten Platten nach dem vorgeschlagenen Schema jeweils eine System- und eine Daten-Partition befinden, könnten auch weitere Daten in der Daten-Partition gesichert werden – so lange der Platz reicht. Voraussichtlich werde ich aber die Festplatten nur für die Images nutzen, insofern auch nur für die Windows-Arbeitsplatz-Rechner.
Cloud-Storage
Als nächstes geht es in die Cloud. Die auf dem Backup-Server gespeicherten Daten sollen in die im letzten Teil angesprochenen Cloud-Speicherplatz gesichert werden. Dabei ist festzuhalten, dass dieser Cloud-Speicher niemals der einzige Backup-Speicher sein sollte. Natürlich kann man sich nicht vor jedem Unheil oder noch so unmöglichen Fall schützen, aber der Cloud-Speicher dient vor allem als Quelle, falls es lokal doch einmal zu einem größeren Vorfall gekommen sein sollte, etwa Komplettausfall der Hardware durch Brand, Überschwemmung oder ähnlichen Katastrophen. Also in dem Sinne von „wenn alle Stricke reißen“…
Das gilt auch für das direkte Backup auf die Cloud. Bei den bei Providern betriebenen VMs beispielsweise ist ein erstes Backup auf den Cloud-Storage meist einfacher und vor allem schneller aufgrund der höheren Bandbreite. So lasse ich etwa jede Nacht ein Backup von diesem Blog auf den Cloud-Storage durchführen (Details siehe in einem weiteren Artikel). Aber in dem Fall wird das Backup nicht nur bei einem Anbieter gespeichert, sondern auf zwei Cloud-Speichern an zwei unterschiedlichen Orten.
Bei einem umfassenderen, noch einzurichtenden Backup werde ich hingegen alle Daten, die von dem Provider-VMs gesichert werden, auf den lokalen Backup-Server kopieren. Insofern läuft die Kette dabei anders herum – als erste Backup-Instanz fungiert die Cloud, als Sicherung davon wiederum der lokale Backup-Server.
Backup-Software
Eigentlich sollte der zweite Teil des Artikels zum Backup genau das Thema Backup-Software zum Inhalt haben. Aber Software ohne Konzept ist genauso sinnlos wie umgekehrt. Um es nicht zu lang werden zu lassen, werde ich mich dem Thema Software daher in einem nächsten Teil widmen. Das wird dann der dritte Teil des Zweiteilers.


