
Vor kurzem habe ich ein neues Docker-Image veröffentlicht, was Duplicity sowie einfache Backup- und Restore-Skripte beinhaltet. Zwar gab es zu dem Zeitpunkt bereits einige Docker-Images mit Duplicity, aber ich wollte ein einfaches Backup-Skript hinterlegen, was die Benutzung von Duplicity angesichts der recht umfassenden Optionen ein wenig vereinfacht.
Der Hintergrund ist leicht erklärt – Duplicity hat nicht wenige Abhängigkeiten, es benötigt etliche Python-Libraries. Zwar ist Duplicity in den meisten Linux-Distributionen enthalten, doch damit möglicherweise in älteren Versionen, andererseits bedarf es auch damit der Installation auf dem zu sichernden System. Da ich mir diese Schritte etwas vereinfachen wollte, lag die Idee eines Docker-Images nahezu auf der Hand. Zuvor hatte ich Derartiges bereits mit einer angepassten Backup-Skript-Fassung für die Speicherung auf Amazon S3 gebaut. Damit werden seit geraumer Zeit Backups erstellt, einen Restore-Prozess hatte ich auch bereits hinter mir, insofern wollte ich dies nun wieder verallgemeinern.
Das Docker-Image besteht letztlich aus dem Basissystem mit Ubuntu, hinzu kommt Duplicity aus dem Releases-PPA und wird ergänzt durch das Backup-Skript aus dem Hetzner-Wiki.
Konzepte
Docker-Container können schnell gestartet und auch wieder beendet werden. Duplicity wird üblicherweise durch ein Kommando inkl. Optionen auf der Kommandozeile gestartet, dasselbe gilt für das Backup-Skript. Der Docker-Container läuft somit nicht dauerhaft bzw. als Daemon, sondern wird bei Bedarf einfach auf dem Host gestartet, oder auch automatisch gesteuert per Cronjob. Der Overhead durch Docker ist minimal, erst recht in Relation zur gesamten Laufzeit des Backup-Prozesses.
Wird ein Docker-Container gestartet, läuft dieser zunächst in einem eigenen (layered) Filesystem, d.h. basierend auf den Images gibt es für den jeweiligen Container einen Layer, auf dem abweichende Dateien geschrieben werden können. Damit hätte ein Programm innerhalb des Containers zwar Zugriff auf die zum Container gehörenden Dateien bzw. Verzeichnisse, aber noch nicht auf Verzeichnisse des Hosts. Jedoch sollen Verzeichnisse des Hosts gesichert werden, während das Docker-Image jederzeit wieder hergestellt werden kann. Der Container soll „ephemeral“ bleiben (vergänglich, kurzlebig), was hier sogar bedeutet, dass er nach jedem Backup-Lauf wieder zerstört wird (Option --rm).
Somit müssten die zu sichernden Verzeichnisse des Hosts als Volumes in den Docker-Container gemountet werden. Bei Benutzung des Backup-Skriptes ist dafür das Verzeichnis ‚/bak‚ vorgesehen, z.B. falls das /home-Verzeichnis des Hosts gesichert werden soll, ist es vom Container aus unter ‚/bak/home/‚ erreichbar. Da beliebig viele Verzeichnisse in den Container gemountet werden können, können grundsätzlich auch Backups von mehreren Verzeichnissen mit einem Container-Lauf durchgeführt werden.
Beim ersten Backup-Lauf ist die Option „full“ mit anzugeben. Damit wird ein Komplettbackup erstellt, was standardmäßig auch am jeweils Ersten eines Monats stattfindet. Wenn das Backup-Skript ohne „full“ bzw. nicht an einem Ersten eines Monats aufgerufen wird, werden inkrementelle Backups erstellt, d.h. es werden nur die Unterschiede zum letzten Voll-Backup gespeichert.
Im Folgenden ein Bespiel für das Erstellen von Backups auf einer Hetzner StorageBox, die mir als Ziel für ein „Cloud-Backup“ dient. Auch wenn es inzwischen nach Werbung aussehen mag – das soll es nicht sein. Das Prinzip lässt sich auf jede Art Online-Speicher übertragen.
Beispiel
Zunächst empfiehlt es sich – sofern möglich – das Anlegen eines eigenen Accounts für das Backup des jeweiligen Servers. Damit soll verhindert werden, dass bei Kompromittierung eines Zugangs alle Backup-Daten betroffen sind.
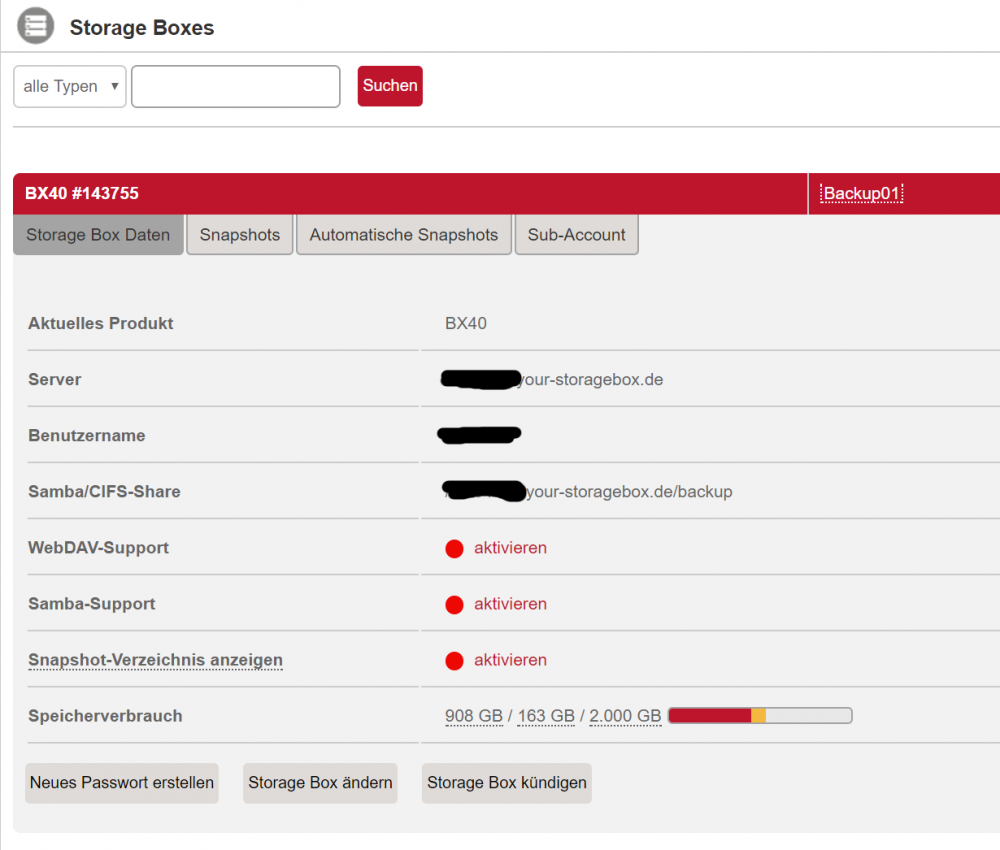
Bei der StorageBox lässt sich dies mit den so genannten Sub-Accounts erledigen. Da ich bereits einige Verzeichnisse bzw. Accounts für Backup- und andere Zwecke angelegt habe, sieht die Übersicht der Sub-Accounts wie folgt aus:
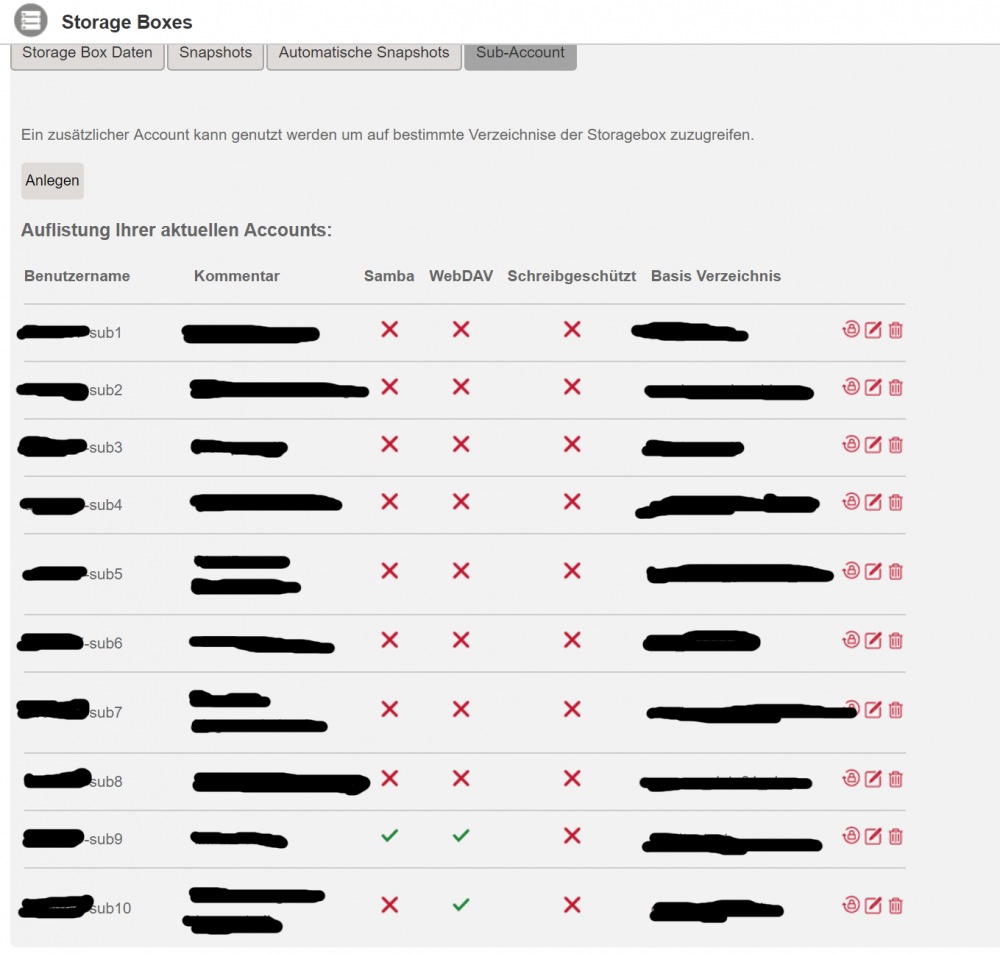
Bevor ein Sub-Account angelegt wird, sollte per FTP-Client (Zugang per SFTP ist natürlich ebenfalls möglich) ein eigenes Verzeichnis für den neuen Sub-Account angelegt werden:
Dazu nutze ich WinSCP und die Zugangsdaten des Haupt-Accounts. Damit besteht Zugriff auf alle Verzeichnisse, insofern auch auf die oberste Ebene.
Danach kann der neue Sub-Account angelegt werden. Nach Klick auf „Anlegen“ erscheint folgendes Formular, in dem das soeben angelegte Basis-Verzeichnis ausgewählt wird:
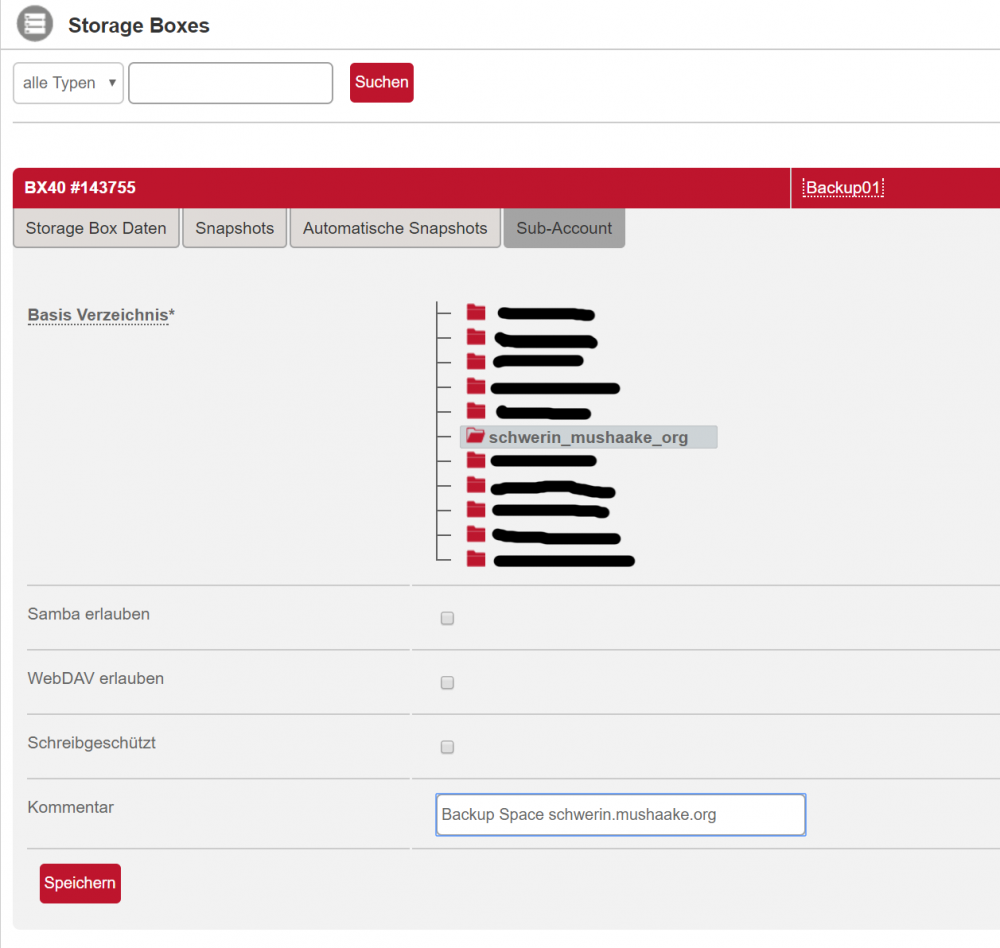
Als Kommentar gebe ich den Zweck des Sub-Accounts an – einfach der Ordnung halber. Nach dem Klick auf „Speichern“ werden die Zugangsdaten bzw. insbesondere das Passwort genannt. Diese müssten unbedingt notiert werden, denn sie werden nur ein einziges Mal angezeigt. Es ist jedoch möglich, das Passwort neu generieren zu lassen.
Damit sind die Vorbereitungen abgeschlossen, nun kann Duplicity bzw. das Backup-Skript zum Einsatz kommen.
Backup-Quellen
Zunächst stellte sich die Frage, was auf dem Server gesichert werden muss. Da die Dienste auf dem Host bereits durch Docker bereit gestellt werden, reicht es aus, wenn die jeweiligen Verzeichnisse, in denen die Docker-Container ihre Daten speichern, eine Sicherung erhalten. Mehr ist in diesem Fall eigentlich nicht notwendig, wobei dies natürlich von den jeweiligen Bedürfnissen abhängt. Im Notfall würde es mir reichen, den Server einfach neu aufzusetzen, die Docker-Daten-Verzeichnisse wieder herstellen zu können und anschließend die Docker-Dienste neu zu starten. Das würde zwar bedeuten, dass während dieser Arbeiten der Server nicht zur Verfügung steht, aber in dem Fall handelt es sich nicht um ein kritisches Umfeld. In einem Unternehmen sieht dies möglicherweise anders aus, doch dafür gibt es dann auch andere Backup-Mechanismen.
Auf dem Host liegen alle Docker-Daten-Verzeichnisse in ‚/srv/docker/‚:
geschke@schwerin:~$ ls -l /srv/docker/ insgesamt 16 drwxr-xr-x 4 root root 4096 Aug 2 2015 bind drwxr-xr-x 5 root root 4096 Jun 6 2015 gitlab drwxr-xr-x 5 root root 4096 Nov 3 2015 nginx drwxr-xr-x 4 root root 4096 Nov 3 2015 registry
Anstatt ein Backup für alle Verzeichnisse zu erzeugen, habe ich mich dafür entschieden, die jeweiligen Verzeichnisse einzeln zu sichern, d.h. ein Backup für „bind“, eines für „gitlab“ usw.. Damit ließen sich einzelne Dienste bzw. deren Daten unabhängig voneinander wiederherstellen.
Für das bei der symmetrischen Verschlüsselung der Backup-Daten benötigte Passwort generiere ich mir einen längeren String:
geschke@schwerin:~$ pwgen -n 96
Ein Komplettbackup
Der erste Aufruf mit Parameter „full“ sieht somit wie folgt aus:
docker run -it --rm --name dup \ -e "GPG_PASSPHRASE=GENERIERTES_PASSWORT" \ -e "BPROTO=ftp" \ -e "BUSER=username-sub11" \ -e "BHOST=username.your-storagebox.de" \ -e "BPASSWORD=PASSWORT_BACKUP_SPACE" \ -e "BDIRS=bind gitlab nginx registry" \ -e "BPREFIX=schwerin" \ --volume /srv/docker/bind:/bak/bind \ --volume /srv/docker/gitlab:/bak/gitlab \ --volume /srv/docker/nginx:/bak/nginx \ --volume /srv/docker/registry:/bak/registry \ geschke/duplicity backup full
Als Environment-Parameter werden übergeben:
- das Passwort für GPG (GPG_PASSPHRASE)
- die Zugangsdaten und Server für den Backup-Space, d.h. der soeben generierte StorageBox-Account (Username BUSER, Protokoll FTP, Backup-Server BHOST und das Passwort in BPASSWORD)
- die zu sichernden Verzeichnisse in BDIRS
- und ein Prefix, hier der Kurzname des zu sichernden Servers
Dabei korrespondieren die Namen der zu sichernden Verzeichnisse (BDIRS) mit den in den Container gemounteten Verzeichnissen. Soll heißen, im Container sind unter /bak/bind, /bak/gitlab usw. die Host-Verzeichnisse erreichbar. Die Angabe in BDIRS bestimmt nun, unabhängig von den gemounteten Verzeichnissen, welche Backups erstellt werden sollen. Somit ist es möglich, z.B. zu Testzwecken ein Verzeichnis auszuschließen, ohne die Angabe der Volumes zu verändern.
Duplicity gibt einige Meldungen aus, am Ende sollte das Backup erfolgreich geschrieben worden sein, so dass die „Backup Statistics“ ausgegeben werden. Diese erscheinen in einer Form ähnlich wie dieser:
--------------[ Backup Statistics ]-------------- StartTime 1501263844.61 (Fri Jul 28 17:44:04 2017) EndTime 1501263847.36 (Fri Jul 28 17:44:07 2017) ElapsedTime 2.75 (2.75 seconds) SourceFiles 825 SourceFileSize 1106909 (1.06 MB) NewFiles 825 NewFileSize 1106909 (1.06 MB) DeletedFiles 0 ChangedFiles 0 ChangedFileSize 0 (0 bytes) ChangedDeltaSize 0 (0 bytes) DeltaEntries 825 RawDeltaSize 1057819 (1.01 MB) TotalDestinationSizeChange 295076 (288 KB) Errors 0 -------------------------------------------------
Bei einem Komplett-Backup dürften die Angaben etwas anders ausfallen, die hier dargestellte Ausgabe stammt von einem inkrementellen Backup.
Inkrementelles Backup
Das Komplett-Backup mit Parameter „full“ ist nur einmal notwendig, danach können inkrementelle Backups ausgeführt werden. Das Kommando dazu ist das o.g. Kommando ohne den Parameter „full“:
docker run -it --rm --name dup \ -e "GPG_PASSPHRASE=GENERIERTES_PASSWORT" \ -e "BPROTO=ftp" \ -e "BUSER=username-sub11" \ -e "BHOST=username.your-storagebox.de" \ -e "BPASSWORD=PASSWORT_BACKUP_SPACE" \ -e "BDIRS=bind gitlab nginx registry" \ -e "BPREFIX=schwerin" \ --volume /srv/docker/bind:/bak/bind \ --volume /srv/docker/gitlab:/bak/gitlab \ --volume /srv/docker/nginx:/bak/nginx \ --volume /srv/docker/registry:/bak/registry \ geschke/duplicity backup
Das war es auch schon! Dieses Kommando kann z.B. per Cronjob regelmäßig ausgeführt werden, so dass immer ein aktuelles Backup vorhanden ist. Nach einem Full- und einem inkrementellen Backup befinden sich folgende Dateien auf dem Backup-Server (hier am Beispiel des Backups von ‚/bak/registry‚:
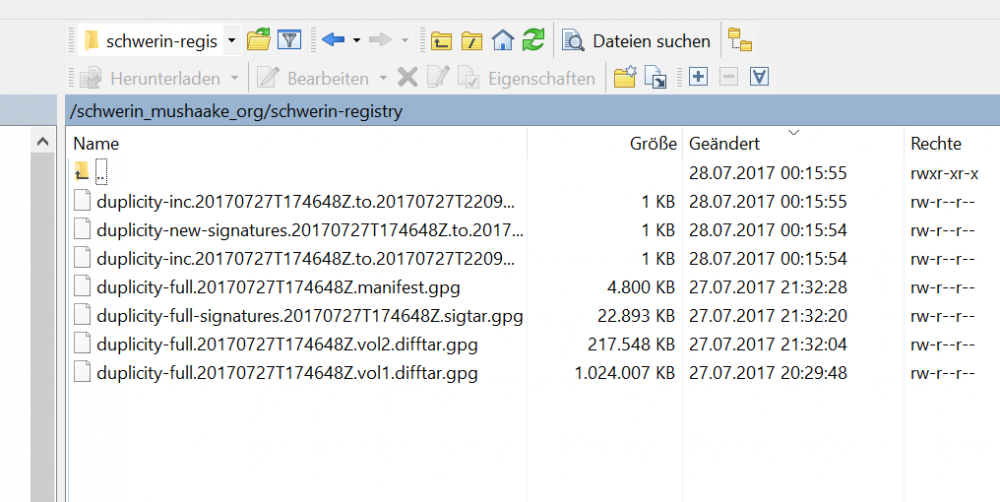
Der Restore-Vorgang ist genauso einfach, mehr dazu möglicherweise in einem späteren Artikel.
FTP vs. SCP vs. SFTP…
Im Beispiel habe ich FTP als Protokoll genutzt. Duplicity beherrscht ca. 25 verschiedene Protokolle, so dass nahezu jeder Backup-Space genutzt werden kann. Die gebräuchlichsten Protokolle dürften weiterhin FTP, SCP und SFTP sein. Mit FTP ist es ganz einfach, leider jedoch auch unverschlüsselt, d.h. sowohl die Dateiübertragung als auch die Übertragung der Steuerdaten wie Username, Passwort usw. werden nicht verschlüsselt. Während die Nutz-Daten bereits vorab per GPG verschlüsselt werden, ist die unverschlüsselte Übertragung von Passwörtern natürlich eher kritisch zu sehen.
Verbindungsprobleme
Somit wäre der Gebrauch von SCP bzw. SFTP sehr zu empfehlen. Die Unterschiede sind eher marginal, sowohl SCP als auch SFTP basieren auf SSH. SCP ist nur für die Dateiübertragung zuständig, während für das Einloggen und die Verbindung SSH genutzt wird. SFTP basiert nicht, trotz des ähnlichen Namens, auf FTP, sondern ist ein eigenständiges Protokoll, was SCP um Dateioperationen erweitert.
Die Kombination der Nutzung des Docker-Containers mit Duplicity macht die Sache jedoch nicht einfacher. Duplicity selbst greift für die Verwendung von SCP und SFTP auf Libraries zurück, die teilweise ein völlig unterschiedliches Verhalten aufweisen. Anstatt als Protokoll nur „scp“ bzw. „sftp“ anzugeben, kann Duplicity auch die zu benutzende Library als Teil des Protokollnamens genannt werden, z.B. „paramiko+sftp“ oder „pexpect+scp“. Mehr Auskunft gibt die Manpage von Duplicity. Als Default wird „paramiko“ genutzt, eine Python-Implementierung des SSHv2-Protokolls.
Das Einloggen per SSH auf einen zuvor nicht genutzten Server endet normalerweise in der Frage, ob die Verbindung aufgebaut werden soll. Denn der Public Key des SSH Servers ist bis dato unbekannt, erst nach Bestätigen der Warnung wird er dem eigenen known_hosts-File hinzugefügt. Theoretisch sollte man sich den Public Key natürlich vorher aus einer sicheren Quelle besorgt haben…
Nun benutzen sowohl SCP als auch SFTP SSH, genauer gesagt die Python-Paramiko-Library. Wenn Duplicity versucht, sich per SSH auf den Backup-Server zu verbinden, erscheint somit ebenfalls die Frage nach der Bestätigung des Public Keys. Nur gilt dies für den User innerhalb des Containers. Und sofern der Container nach dem Betrieb wieder entfernt würde, wäre jedes Mal eine Bestätigung notwendig. Das ist nicht nur unschön, sondern man müsste auch beim Start des Backups aktiv eingreifen, insofern wäre kein automatischer Lauf möglich.
Um hier Abhilfe zu schaffen, habe ich einige Experimente durchgeführt, zunächst SSH-Parameter geändert, so dass innerhalb des Containers die Verbindung ohne die Rückfrage möglich gewesen wäre. Per SSH hat dies funktioniert, wenngleich die Methode natürlich gewisse Risiken mit sich brachte. Die Paramiko-Library hat jedoch sämtliche Einstellungen konsequent ignoriert, sowohl als Option übergeben (--ssh-options="-oUserKnownHostsFile=/dev/null" --ssh-options="-oStrictHostKeyChecking=no„), was auch laut Manpage korrekt war, als auch mit spezieller ‚.ssh/config‘-Datei bzw. globaler ‚/etc/ssh/ssh_config‚. Die Nutzung von „pexpect“, d.h. Protokoll „pexpect+scp://“ bzw. „pexpect+sftp://“ schien zunächst vielversprechender, d.h. die SSH-Public-Key-Frage erschien nicht. Jedoch funktionierte dies letztlich überhaupt nicht – nach einer längeren Wartezeit, die nicht so lang sein konnte, habe ich abgebrochen.
Die Docker-Lösung
Doch man kann nicht nur Verzeichnisse, sondern auch Dateien in den Docker-Container mounten. Also auch eine vorhandene .ssh/known_hosts-Datei, so dass Duplicity bzw. Paramiko/SSH darauf zurückgreifen können. Dabei ist jedoch darauf zu achten, dass das Format der Keys Paramiko gefällt. D.h. wenn man zunächst vom Host aus versucht, SSH zur Erstellung der notwendigen Zeile in known_hosts zu verwenden, könnte es sein, dass dies je nach Konfiguration von SSH bzw. verwendetem Key-Format ebenfalls nicht zum Erfolg führt.
Die entsprechende Zeile lässt sich erzeugen mit:
geschke@schwerin:~$
ssh-keyscan -t rsa username.your-storagebox.de >> .ssh/known_hosts
# username.your-storagebox.de:22 SSH-2.0-mod_sftp/0.9.9
Danach kann die betreffende known_hosts-Datei in den Container gemountet werden, so dass der Aufruf insgesamt wie folgt aussieht:
docker run -it --rm --name dup \ -e "GPG_PASSPHRASE=GENERIERTES_PASSWORT" \ -e "BPROTO=ftp" \ -e "BUSER=username-sub11" \ -e "BHOST=username.your-storagebox.de" \ -e "BPASSWORD=PASSWORT_BACKUP_SPACE" \ -e "BDIRS=bind gitlab nginx registry" \ -e "BPREFIX=schwerin" \ --volume /srv/docker/bind:/bak/bind \ --volume /srv/docker/gitlab:/bak/gitlab \ --volume /srv/docker/nginx:/bak/nginx \ --volume /srv/docker/registry:/bak/registry \
–volume /home/geschke/.ssh/known_hosts:/root/.ssh/known_hosts \
geschke/duplicity backup
Ich habe hier die known_hosts-Datei meines Users verwendet, statt dessen könnte auch eine eigene genutzt werden bzw. ein spezieller Backup-User angelegt werden. Dieser müsste lesend auf die zu sichernden Verzeichnisse zugreifen dürfen.
Fazit
Wie immer führen viele Wege zum Ziel, Duplicity bietet immerhin einen erprobten Weg zum Backup, mit Docker lässt sich die Installation inkl. etlicher Abhängigkeiten ein wenig vereinfachen, dafür ist das SSH-Key-Management etwas komplexer. Zwischenzeitlich hatte ich sogar daran gedacht, statt Duplicity ein Docker-Image mit Duplicati zu erstellen, denn Duplicati bietet nicht nur eine web-basierte GUI, sondern lässt sich auch per Kommandozeile bedienen. Doch das hätte sicherlich zu anderen Problemen geführt, die erst einmal hätten gelöst werden müssen. Um vorweg zu greifen – auf Client-PCs bzw. unter Windows und MacOS verwende ich Duplicati sehr gerne, während andere Backup-Programme eher zu einer gewissen Verärgerung geführt haben. Das ist aber wiederum Thema eines späteren Artikels…


")
