
Seit den ersten Tests und dem Aufbau eines Docker Swarm Clusters unter Docker 1.12 mit dem so genannten Swarm mode habe ich mich weiter mit den neuen Features von Docker 1.12 beschäftigt. Bevor ich jedoch zu einem ausführlicheren Beitrag über Docker Services in der Praxis komme, möchte ich zunächst einige Themen erläutern, die mir beim weiteren Ausprobieren aufgefallen sind.
Node-Rollen ändern – Worker zu Manager
Ein weiterer zu Testzwecken aufgebauter Swarm sieht wie folgt aus:
geschke@waren:~$ docker node ls ID HOSTNAME MEMBERSHIP STATUS AVAILABILITY MANAGER STATUS 082s07yjictb73ch10aerioq4 chemnitz Accepted Ready Active 5rbu26ms9zp8uw7fu3cc0uydr schwerin.mushaake.org Accepted Ready Active 81jpd9k6kc05dnwca0msqgm6j frankfurt Accepted Ready Active bcuny83lllnn37vrxbwc2r5gi rostock Accepted Ready Active Reachable cydggci6rmv923krcvl17po5e * waren Accepted Ready Active Leader
Dabei fällt zunächst auf, dass „schwerin.mushaake.org“ einen FQDN (fully qualified domain name) als Hostname hat, während die anderen nur die Kurzbezeichnung tragen. Das liegt daran, dass der Hostname auf „schwerin“ im Unterschied zu den anderen Nodes in der Datei /etc/hostname mit Domain angegeben ist – warum auch immer.
Nun sind in diesem Cluster zwei Manager Nodes enthalten – und zwar „waren“ und „rostock“. Diesen sollte ein dritter Manager hinzu gefügt werden, was mit dem Kommando „docker node promote <hostname>“ möglich sein sollte:
geschke@waren:~$ docker node promote chemnitz Node chemnitz promoted to a manager in the swarm.
Das Ergebnis war jedoch ernüchternd:
geschke@waren:~$ docker node ls ID HOSTNAME MEMBERSHIP STATUS AVAILABILITY MANAGER STATUS 082s07yjictb73ch10aerioq4 chemnitz Accepted Ready Active 5rbu26ms9zp8uw7fu3cc0uydr schwerin.mushaake.org Accepted Ready Active 81jpd9k6kc05dnwca0msqgm6j frankfurt Accepted Ready Active bcuny83lllnn37vrxbwc2r5gi rostock Accepted Ready Active Reachable cydggci6rmv923krcvl17po5e * waren Accepted Ready Active Leader
Der Node „chemnitz“ war offensichtlich noch kein Manager, was auch ein Test bestätigte:
geschke@chemnitz:~$ docker node ls Error response from daemon: This node is not a Swarm manager. Worker nodes can't be used to view or modify cluster state. Please run this command on a manager node or promote the current node to a manager.
Eine weitere Fehlermeldung war nicht zu erkennen, und während sich die genannten Nodes problemlos als Worker hinzufügen ließen, war die Ernennung zum Manager nicht möglich.
Woran das lag, hatte sich mir zunächst nicht erschlossen. Daher wollte ich das Verhalten auf einem anderen Swarm verifizieren. Dabei handelt es sich um denjenigen aus dem letzten Artikel, mehrere VMs auf drei physischen Servern in einem privaten Netzwerk:
ID HOSTNAME MEMBERSHIP STATUS AVAILABILITY MANAGER STATUS 28v6jjr50etv4sjmx5p4yuhmp lausen Accepted Ready Active 2hwa815cxk6pf8bh4mo7hkx11 tolkewitz Accepted Ready Active 3eg4vn9io09v0046tmuwibsa5 lindenau Accepted Ready Active 64nf6p2azvujv291ay4g1nhwl kaditz Accepted Ready Active Reachable 76nj42jlv8ih1lz1yp98juzf7 * tondi Accepted Ready Active Leader 7yte21jbezc7lwznton64bwi8 pirita Accepted Ready Active 9r6mfzv4gflyafi9uwikaaqvf connewitz Accepted Ready Active Reachable cixviuywhxd6qe2pr2f1u7rwd miltitz Accepted Ready Active
Einer der Worker sollte zum Manager ernannt werden:
geschke@tondi:~$ docker node promote lausen Node lausen promoted to a manager in the swarm.
Das Ergebnis:
geschke@tondi:~$ docker node ls ID HOSTNAME MEMBERSHIP STATUS AVAILABILITY MANAGER STATUS 28v6jjr50etv4sjmx5p4yuhmp lausen Accepted Ready Active Reachable 2hwa815cxk6pf8bh4mo7hkx11 tolkewitz Accepted Ready Active 3eg4vn9io09v0046tmuwibsa5 lindenau Accepted Ready Active 64nf6p2azvujv291ay4g1nhwl kaditz Accepted Ready Active Reachable 76nj42jlv8ih1lz1yp98juzf7 * tondi Accepted Ready Active Leader 7yte21jbezc7lwznton64bwi8 pirita Accepted Ready Active 9r6mfzv4gflyafi9uwikaaqvf connewitz Accepted Ready Active Reachable cixviuywhxd6qe2pr2f1u7rwd miltitz Accepted Ready Active
Interessanterweise hatte es diesmal problemlos funktioniert! Also untersuchte ich die Firewall-Einstellungen auf dem betreffenden Node des ersten Swarms, tatsächlich gab es dort eine Ubuntu-ufw-Firewall, jedoch waren die Ports für den Swarm eigentlich freigeschaltet. Eigentlich. Da jedoch der Node „chemnitz“ in einem vollkommen anderen Netzwerk, d.h. bei einem anderen Provider steht als die beiden Manager-Nodes „waren“ und „rostock“, vermute ich an dieser Stelle eine mögliche Ursache. Denn der Node „schwerin“ konnte wiederum zum Manager ernannt werden:
geschke@waren:~/orchestration-workshop/dockercoins$ docker node promote 5rbu26ms9zp8uw7fu3cc0uydr Node 5rbu26ms9zp8uw7fu3cc0uydr promoted to a manager in the swarm. geschke@waren:~/orchestration-workshop/dockercoins$ docker node ls ID HOSTNAME MEMBERSHIP STATUS AVAILABILITY MANAGER STATUS 082s07yjictb73ch10aerioq4 chemnitz Accepted Ready Active 5rbu26ms9zp8uw7fu3cc0uydr schwerin.mushaake.org Accepted Ready Active Reachable 81jpd9k6kc05dnwca0msqgm6j frankfurt Accepted Ready Active bcuny83lllnn37vrxbwc2r5gi rostock Accepted Ready Active Reachable cydggci6rmv923krcvl17po5e * waren Accepted Ready Active Leader
Docker Services
Docker beschreibt die in der Version 1.12 neu hinzu gekommenen Services als „replizierte, verteilte, lastverteilte Prozesse in einem Swarm von Docker Engines“ (“ replicated, distributed, load balanced process on a swarm of Engines“). Letztlich handelt es sich dabei um eine neue Art, Container zu starten, zu verteilen und zu verwalten. Die bisherige Art und Weise funktioniert zwar nach wie vor, ist aber teilweise eingeschränkt. Während es im bisherigen Swarm möglich war, einen Container auch auf einem Host per „docker run...“ zu starten und dabei ein im Swarm angelegtes Overlay-Network zu nutzen, ist dies im neuen Swarm nicht mehr möglich. die Overlay-Networks beziehen sich hier nur noch auf dem Swarm und können nur mit den Services verwendet werden. Da die Beispiele zu den Services bislang eher sagen wir mal sehr beispielhaft sind, habe ich versucht, mich anhand einer realen Anwendung dem Thema zu nähern. Dazu verweise ich (schon wieder) auf den nächsten Artikel. Ein sehr, sehr simples Beispiel ist der Start eines „ping“-Kommandos innerhalb eines Containers. Anstatt diesen einzelnen Container per „docker run...“ zu starten, wird er als Service deklariert:
geschke@connewitz:~$ docker service create --name pingping alpine ping 8.8.8.8 52kd1tkp8vi2vu6ssu5oh5aqc geschke@connewitz:~$ docker service ls ID NAME REPLICAS IMAGE COMMAND 52kd1tkp8vi2 pingping 1/1 alpine ping 8.8.8.8 geschke@connewitz:~$ docker service tasks pingping ID NAME SERVICE IMAGE LAST STATE DESIRED STATE NODE 0vzbr535s4po81o4bdeb8fuzf pingping.1 pingping alpine Running 50 seconds ago Running pirita
An dieser Stelle steht naturgemäß die Frage nach dem „Warum?“. Was ist der Zweck dieser neuen Art? Docker selbst nennt wiederum einige Argumente – Services sind selbstheilend, belastbar, beinhalten ein internes Load-Balancing, repliziert (verteilt oder „global“, d.h. auf jedem Node laufend) und werden deklarativ definiert, d.h. der gewünschte Status wird angegeben, Docker kümmert sich um die Einhaltung. Tatsächlich klingt dies nach einigen großartigen Features – und das sind sie auch, vorausgesetzt, die Anwendung ist dementsprechend darauf ausgelegt.
Im Beispiel wurde der Service einmal gestartet und läuft auf dem Node „pirita“. Durch Constraints ist es auch möglich, die Nodes näher zu spezifizieren, auf denen der Service laufen soll.
Sollen z.B. zehn Container laufen, lässt sich der Service einfach skalieren:
geschke@connewitz:~$ docker service scale pingping=10 pingping scaled to 10 geschke@connewitz:~$ docker service ls ID NAME REPLICAS IMAGE COMMAND 52kd1tkp8vi2 pingping 3/10 alpine ping 8.8.8.8
Wie zu erkennen ist, sind zum Zeitpunkt des Aufrufs der Service-Liste erst drei Container gestartet worden. Das liegt daran, dass die meisten Nodes das zugrunde liegende Image noch nicht heruntergeladen hatten. Das Herunterladen geschieht automatisch, so dass wenig später das Kommando zu diesem und somit gewünschten Ergebnis führt:
geschke@connewitz:~$ docker service ls ID NAME REPLICAS IMAGE COMMAND 52kd1tkp8vi2 pingping 10/10 alpine ping 8.8.8.8
Eine Übersicht der jeweiligen Container erhält man mit dem „docker service tasks <servicename>„-Kommando. Das erste Beispiel zeigt den Status kurz nach dem Aufruf des scale-Befehlt, im zweiten sind bereits alle notwendigen Images heruntergeladen und die Container gestartet worden:
geschke@connewitz:~$ docker service tasks pingping ID NAME SERVICE IMAGE LAST STATE DESIRED STATE NODE 0vzbr535s4po81o4bdeb8fuzf pingping.1 pingping alpine Running 4 minutes ago Running pirita 0s3t480ifto7uajcu2mi1qn8u pingping.2 pingping alpine Preparing 20 seconds ago Running tolkewitz e9shm3bdvxlfbz2w07a7p3vu4 pingping.3 pingping alpine Ready 20 seconds ago Running miltitz 5pwbxnk7ff38syqnprjvc1shh pingping.4 pingping alpine Preparing 20 seconds ago Running lindenau 85811cca8e2kvlztn23ty6re1 pingping.5 pingping alpine Preparing 20 seconds ago Running lindenau 99zqigh5lv9c4wrn4plfa8afl pingping.6 pingping alpine Running 20 seconds ago Running pirita 8s2bpm3tzr5cjh1sgeb4objip pingping.7 pingping alpine Preparing 20 seconds ago Running kaditz 94z47hmv83vte7vvk52weu3hg pingping.8 pingping alpine Running 20 seconds ago Running tondi 8lo0g0f1bjrkll26i6lhbwkv3 pingping.9 pingping alpine Preparing 20 seconds ago Running lausen 3y9z5l21psjctt17ozlt7p59e pingping.10 pingping alpine Running 20 seconds ago Running connewitz geschke@connewitz:~$ docker service tasks pingping ID NAME SERVICE IMAGE LAST STATE DESIRED STATE NODE 0vzbr535s4po81o4bdeb8fuzf pingping.1 pingping alpine Running 6 minutes ago Running pirita 0s3t480ifto7uajcu2mi1qn8u pingping.2 pingping alpine Running 2 minutes ago Running tolkewitz e9shm3bdvxlfbz2w07a7p3vu4 pingping.3 pingping alpine Running 2 minutes ago Running miltitz 5pwbxnk7ff38syqnprjvc1shh pingping.4 pingping alpine Running 2 minutes ago Running lindenau 85811cca8e2kvlztn23ty6re1 pingping.5 pingping alpine Running 2 minutes ago Running lindenau 99zqigh5lv9c4wrn4plfa8afl pingping.6 pingping alpine Running 2 minutes ago Running pirita 8s2bpm3tzr5cjh1sgeb4objip pingping.7 pingping alpine Running 2 minutes ago Running kaditz 94z47hmv83vte7vvk52weu3hg pingping.8 pingping alpine Running 2 minutes ago Running tondi 8lo0g0f1bjrkll26i6lhbwkv3 pingping.9 pingping alpine Running 2 minutes ago Running lausen 3y9z5l21psjctt17ozlt7p59e pingping.10 pingping alpine Running 2 minutes ago Running connewitz
Die umgekehrte Richtung geht natürlich auch:
geschke@connewitz:~$ docker service scale pingping=1 pingping scaled to 1 geschke@connewitz:~$ docker service tasks pingping ID NAME SERVICE IMAGE LAST STATE DESIRED STATE NODE 0s3t480ifto7uajcu2mi1qn8u pingping.2 pingping alpine Running 5 minutes ago Running tolkewitz
Hier wurden alle Container bis auf die Nr. 2 beendet, Docker sorgt für die Einhaltung der Vereinbarung, denn es soll nur genau ein Task laufen. An dieser Stelle wird auch klar, dass die jeweiligen Tasks und somit zugrunde liegenden Images für derartige Aktionen ausgelegt sein müssen. Docker gewährleistet hier die Einhaltung der Deklaration, aber es ist nicht festgelegt, in welcher Reihenfolge die Container gestartet werden bzw. dass der zuerst gestartet auch derjenige ist, der beim Herunterskalieren übrig bleibt.
Der Service kann genauso einfach wieder beendet werden:
geschke@connewitz:~$ docker service tasks pingping ID NAME SERVICE IMAGE LAST STATE DESIRED STATE NODE 0s3t480ifto7uajcu2mi1qn8u pingping.2 pingping alpine Running 5 minutes ago Running tolkewitz geschke@connewitz:~$ docker service rm pingping pingping geschke@connewitz:~$ docker service ls ID NAME REPLICAS IMAGE COMMAND
Zwar liegt die praktische Anwendung eines solchen Beispiels in weiter Ferne, aber ich wollte dennoch zur leichteren Nachvollziehbarkeit die Kommandos in dieser Form erläutern.
Docker Swarm Visualizer
Ein sehr nettes Tool, was im Vorstellungs-Video von Docker 1.12 verwendet wurde, ist der Docker Swarm Visualizer. Damit lassen sich die neuen Docker Services in einem Swarm übersichtlich anzeigen. Die Aktualisierung geschieht nahezu in Echtzeit, somit können Änderungen in der Anzahl und Verteilung sehr gut nachvollzogen werden.
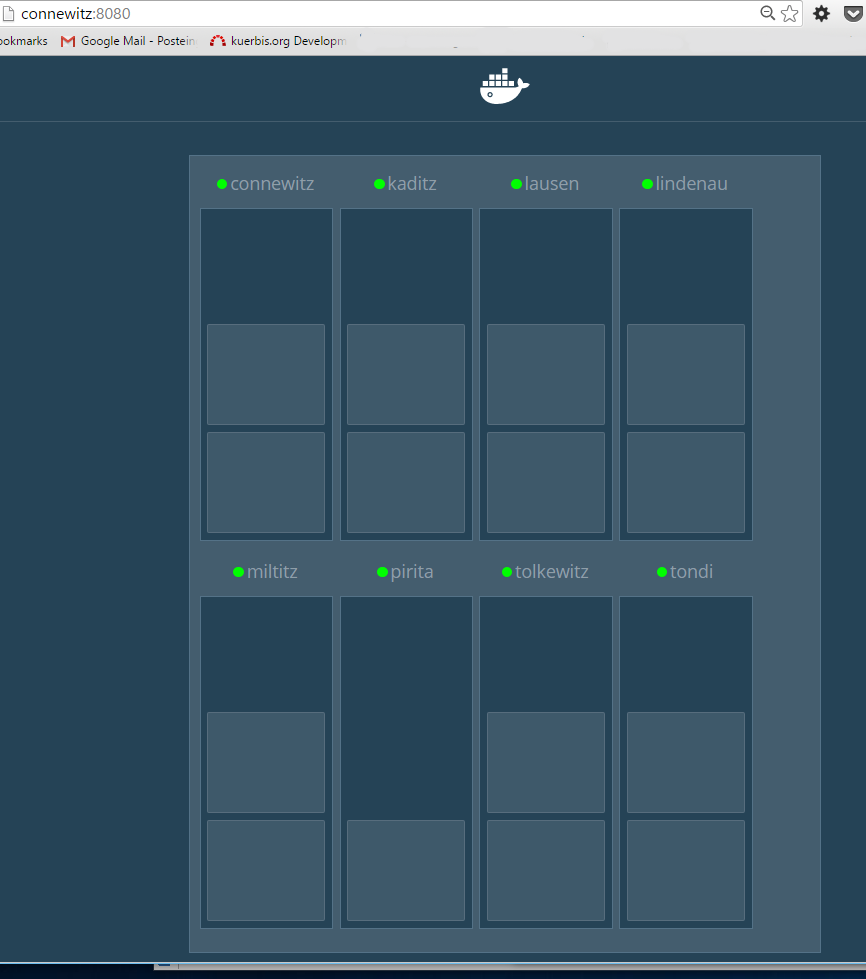
Der Start ist denkbar einfach, hier wurde auf einem der Manager Nodes folgendes Kommando verwendet:
docker run -it -d -p 8080:8080 --name="swarmvisualizer" -e HOST=connewitz -v /var/run/docker.sock:/var/run/docker.sock manomarks/visualizer
Weitere Hinweise finden sich auf der Github-Seite, auf jeden Fall lohnt sich das Ausprobieren!
Fazit
Docker 1.12 mit dem neuen Swarm mode bietet etliche neue Features, die jedoch erst einmal ausprobiert und beherrscht werden müssen. Bei den Services war ich anfangs eher skeptisch bzw. nach den ersten Versuchen ernüchtert, später jedoch umso begeisterter. Dazu später mehr…



Bei mir werden tasks bei einem alpine image beendet. Ich kann also quasi keine services bestehend aus mehreren tasks mit dem alpine baseimage starten und laufen lassen. Sie werden gestartet, laufen und enden dann wieder…
Das kann natürlich eine Vielzahl von Ursachen haben. Ich würde hier systematisch vorgehen, z.B. erstmal versuchen, den Container nicht als Service zu starten. Falls es läuft, ist man einen Schritt weiter. Falls nicht, stellt sich die Frage, was überhaupt gestartet wird – ist ein Daemon à la Supervisord enthalten oder wird die Anwendung direkt gestartet usw.. Wenn es ganz hardcore ist, starte ich meist einen Container mit dem betreffenden Image, lasse aber eine beliebige Shell laufen, etwa:
docker run -d -it --name test ubuntu:bionic bash
Dann kann man in den laufenden Container „einsteigen“:
docker exec -it test bash
Von dort aus rufe ich dann die Anwendung so auf, wie sie ansonsten beim Start des Containers aufgerufen wird. Wenn sie sich nicht direkt beendet – ok, bestens. Wenn doch, habe ich meist nicht die richtigen Start-Parameter genutzt.
Funktioniert das alles, liegt das Problem an anderer Stelle, dann kommt der Swarm mode ins Spiel. Hier lässt sich ohne genauere Details zu kennen, schwer raten. Ich hatte beispielsweise bereits DNS-Probleme, die dazu führten, dass die Container sich wieder beendeten, da die Dienste sich nicht gegenseitig finden konnten. Ebenfalls gab es Probleme, dass manche Nodes mit einer anderen Docker-Version bestückt waren – hier hat ein Update auf eine einheitliche Version geholfen. Ich würde auch versuchen, schnell genug zu sein (meist rennen die Container ja ein, zwei Sekunden, bis sie wieder gestoppt werden) und während der kurzen Laufzeit einen Blick ins Log zu erhaschen, oft kann man die Ursache dort herausfinden. Und dann weiter entlang hangeln.