
Ausgehend vom ersten Beispiel der Docker Services aus dem Blog-Beitrag von Docker selbst, habe ich mich gefragt, wie eine klassische PHP-Anwendung als Docker-Service aussehen würde. Einer kurzen Einführung in die neuen Docker-Services habe ich im letzten Beitrag einen Abschnitt gewidmet, der folgende Text geht davon aus, dass ein Docker Swarm im neuen Swarm mode erfolgreich eingerichtet wurde.
Ein erstes Beispiel
Eines der neuen Features von Docker ist der eingebaute Load-Balancer. Dabei handelt es sich eigentlich um einen alten Bekannten, denn hier verwendet Docker den IPVS (IP Virtual Server) für so genanntes Layer-4-Switching, der sich seit ca. 15 Jahren im Linux-Kernel befindet. Das folgende Beispiel stammt somit direkt aus dem bereits zitierten Blog-Beitrag, der Swarm Cluster sieht wie folgt aus:
geschke@waren:~$ docker node ls ID HOSTNAME MEMBERSHIP STATUS AVAILABILITY MANAGER STATUS cbzv67j025owtpjhxv3my8dyd schwerin.mushaake.org Accepted Ready Active Reachable cfp7ajyrm1xnlrz1l3siup6qb * waren.mushaake.org Accepted Ready Active Leader ed558w0v3im5rfp53zqhrf4ps rostock.mushaake.org Accepted Ready Active Reachable
Nun wird die „vote“-Anwendung gestartet, zunächst nur ein Task:
geschke@waren:~$ docker service create --name vote -p 8080:80 instavote/vote a4sl6cj2nrrdu0hvvs51pfcvb geschke@waren:~$ docker service ls ID NAME REPLICAS IMAGE COMMAND a4sl6cj2nrrd vote 1/1 instavote/vote geschke@waren:~$ docker service tasks vote ID NAME SERVICE IMAGE LAST STATE DESIRED STATE NODE 1gql8v8x9kbo702kqu21iwhpa vote.1 vote instavote/vote Running 5 minutes ago Running waren.mushaake.org
Laut Beispiel müsste nun tatsächlich der Port 8080 auf allen beteiligten Nodes verfügbar sein und die Einstiegsseite der Anwendung darstellen. Tatsächlich ist genau dies der Fall, wie die nächsten Screenshots zeigen – gleichgültig auf welchen der Nodes man sich bewegt, die Antwort wird vom gleichen Container generiert.
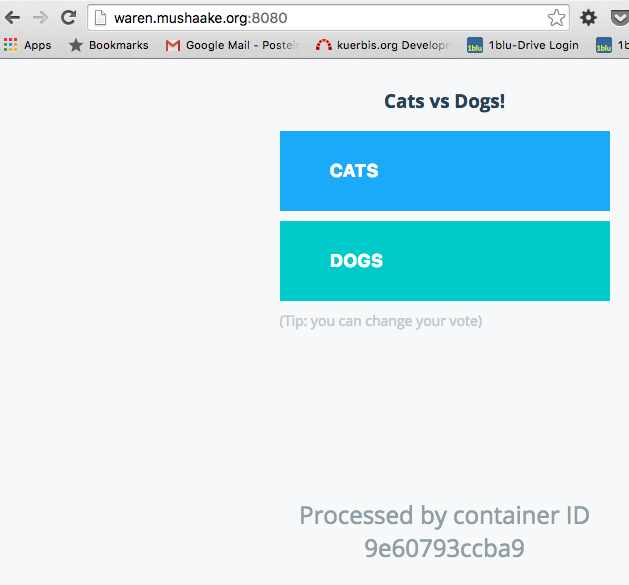
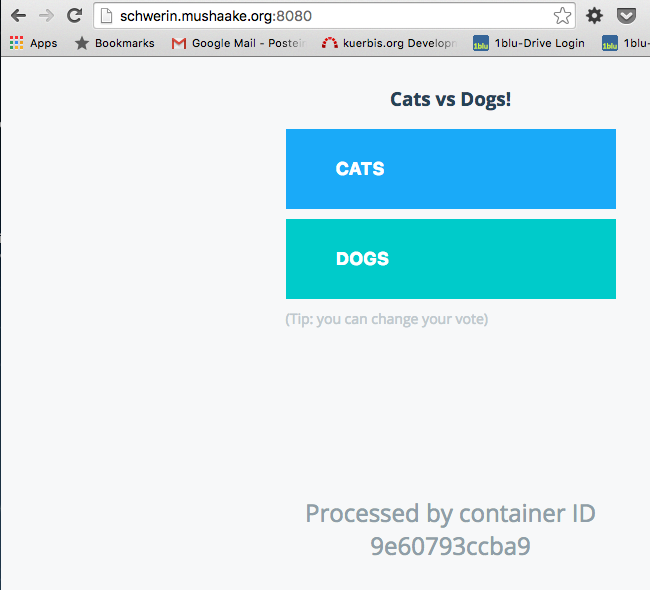
Damit die Anwendung vollständig läuft, wäre zwar noch ein Overlay-Network und eine darüber ansprechbare Redis-Datenbank notwendig, dies ist aber hier vernachlässigbar.
Natürlich funktioniert das Scale-Kommando wie bereits gezeigt und erwartet:
geschke@waren:~$ docker service scale vote=3 vote scaled to 3 geschke@waren:~$ docker service tasks vote ID NAME SERVICE IMAGE LAST STATE DESIRED STATE NODE 1gql8v8x9kbo702kqu21iwhpa vote.1 vote instavote/vote Running 11 minutes ago Running waren.mushaake.org 4z4ke4z52cz0xvb2c1gbs7a5e vote.2 vote instavote/vote Running 50 seconds ago Running rostock.mushaake.org 74m3raezqrgizeuzoyk3tdsdp vote.3 vote instavote/vote Running 50 seconds ago Running schwerin.mushaake.org
Nun befindet sich auf allen Nodes jeweils ein Task. Das Load-Balancing wird auch dahingehend fortgeführt, als dass bei einem Reload auf derselben URL zufällig einer der Container ausgewählt und angesprochen wird. Ob diese Strategie auch änderbar ist, konnte ich der bisherigen Dokumentation nicht wirklich entnehmen, auch der Unterschied der beiden möglichen „endpoint modes“ „vip“ (virtual IP) und „dnsrr“ (DNS Round Robin) verlangt noch einige nähere Erläuterungen.
Ein Image für PHP-FPM
Insgesamt ist dieses eingebaute Load-Balancing-Feature schon ziemlich cool. Nun bringt die Beispiel-Anwendung alles mit bis auf die Datenbank, insofern „Backend“ und „Frontend“ in einem. Wie würde aber z.B. eine klassische PHP-Anwendung als Service aussehen? Aktuell wird häufig PHP als php-fpm-Prozess gestartet, während Nginx als Web-Server genutzt wird. Damit ist bereits eine grundsätzliche Verteilung möglich, so können durch Nginx etwa nicht nur PHP über den Unix-Socket auf dem lokalen Rechner angesprochen werden, sondern auch über IP auf weiteren Rechnern. Üblicherweise steht zuletzt noch eine Datenbank, etwa MySQL/MariaDB zur Verfügung, die ebenfalls wieder auf mehreren Nodes ansprechbar ist, sei es durch eine Master-Slave-Konfiguration oder wie bei Galera Cluster als gleichberechtigte Instanzen. Oder vielleicht lieber eine MongoDB als ReplicaSet verwenden? Die Möglichkeiten sind vielfältig, daher klammere ich den Aspekt der Datenbank hier zunächst aus.
Interessanter wird es bereits bei PHP-FPM. Davon ausgehend, dass Nginx und PHP-FPM in unterschiedlichen Containern laufen sollen, müssen für beide Services entsprechende Images generiert werden. Nun ist es jedoch nicht möglich, die PHP-Anwendung, insofern das Verzeichnis, in dem die PHP-Dateien enthalten sind, beim Definieren der Services und somit Start der Container als Volume hinzu zu mounten. Beim Weg per „docker run...„-Kommando war dies noch möglich, weil die Verbindung von Container zu Node viel enger war.
docker service create --name php -p 9000:9000 --volume /home/geschke/docker-php-fpm/test:/var/www/html geschke/php-fpm unknown flag: --volume See 'docker service create --help'.
Das funktioniert also nicht. Insofern müssen die PHP-Quelltexte im Image enthalten sein, was als Service gestartet werden soll. Als Basis-Image habe ich dafür zunächst ein minimales Image für PHP-FPM erstellt: php-fpm.
Zwar existieren etliche, auch offizielle Images für PHP, aber diese sind teilweise für einen sehr speziellen Einsatz oder aber so allgemein gehalten, dass die Konfiguration schwieriger zu verstehen ist als schnell ein minimales Image zu erstellen, was genau diejenigen Module beinhaltet, die man benötigt und noch dazu auf der gewohnten Linux-Distribution basiert.
Mit dem Image ist es auch möglich, ein Volume für den PHP-Quellcode hinein zu mounten, aber für die Verwendung als Service muss ein abgeleitetes Dockerfile erstellt werden. Dies sieht wie folgt aus:
FROM geschke/php-fpm MAINTAINER Ralf Geschke <ralf@kuerbis.org> LABEL last_changed="2016-07-23" WORKDIR /var/www/html COPY html/* /var/www/html/ EXPOSE 9000 CMD ["php-fpm7.0"]
Viel einfacher geht es nicht – der Inhalt des Verzeichnisses „html“ wird in das Image nach /var/www/html/ kopiert. Zum Test befinden sich genau zwei Dateien darin, eine mit dem berühmten Aufruf von phpinfo(), die andere zeigt letztlich auch nur den Server-Namen an, denn dieser wird vom jeweils laufenden Container bzw. Task bestimmt, vgl. die „vote“-Anwendung aus dem Eingangsbeispiel:
[...]
<p>Server name: <?php echo $_SERVER["SERVER_NAME"]; ?></p>
[...]
Also Image bauen und ins private Repository pushen, schließlich müssen derartige Tests nicht unbedingt auf dem Docker Hub landen:
geschke@connewitz:~/docker-php-test$ docker build -t phptestb . geschke@connewitz:~/docker-php-test$ docker tag phptest hub.kuerbis.org:81/phptest geschke@connewitz:~/docker-php-test$ docker push hub.kuerbis.org:81/phptest
Damit ist das Image namens „hub.kuerbis.org:81/phptest“ nun auch erreichbar und kann herunter geladen werden. Vor dem ersten Test wird noch ein Overlay-Network angelegt, was zur Kommunikation zwischen den späteren Nginx-Services und den PHP-FPM-Services dienen soll:
geschke@connewitz:~/docker-php-test$ docker network create -d overlay gnswarm ek325du00636j2xkpawrwwtf2 geschke@connewitz:~$ docker network ls NETWORK ID NAME DRIVER SCOPE 31a05a5c9cae bridge bridge local 812ea049842a docker_gwbridge bridge local ek325du00636 gnswarm overlay swarm 42212f4a4b9b host host local 2jvt0k5zac46 ingress overlay swarm c59912cd4ec8 none null local
Das sieht soweit gut aus, und die Ports 9000, auf denen PHP-FPM lauscht, sollen auch nicht nach außen freigegeben werden. Somit kann der Service gestartet werden:
geschke@connewitz:~/docker-php-test$ docker service create --name phpbackend --network gnswarm --replicas 5 hub.kuerbis.org:81/phptest 22skrcle9mp3pft93urukbv7w geschke@connewitz:~/docker-php-test$ docker service ls ID NAME REPLICAS IMAGE COMMAND 22skrcle9mp3 phpbackend 1/5 hub.kuerbis.org:81/phptest
Das sieht soweit erfolgreich aus, doch befindet sich das Image in einem privaten Repository. Üblicherweise werden die Images automatisch auf den jeweiligen Nodes herunter geladen, sofern sie nicht bereits existieren. Wie sieht dies hier aus?
docker service tasks phpbackend ID NAME SERVICE IMAGE LAST STATE DESIRED STATE NODE 7k8femn25mjttty2tgkjariim phpbackend.1 phpbackend hub.kuerbis.org:81/phptest Accepted 4 seconds ago Accepted kaditz 2fizbz7v0fy6z5ohe0uup5ifr phpbackend.2 phpbackend hub.kuerbis.org:81/phptest Accepted 2 seconds ago Accepted miltitz e0nuu90kkzpeu44z8d9nt0bil phpbackend.3 phpbackend hub.kuerbis.org:81/phptest Running 51 seconds ago Running connewitz e9unueuee9fj8428cmcbicv83 phpbackend.4 phpbackend hub.kuerbis.org:81/phptest Accepted 1 seconds ago Accepted tondi e0utqt66rhs4ugsww8zu7jf1a phpbackend.5 phpbackend hub.kuerbis.org:81/phptest Allocated less than a second ago Accepted
Die Antwort lautet, dass die einzelnen Nodes zwar den Download versuchen, aber dabei zunächst scheitern. Der Status wechselt dabei auch auf „rejected“, da die Credentials für den Download zwar auf dem Client bekannt sind, von dem das Image in das private Repository gepusht wurde (Node „connewitz“), aber die anderen Nodes kennen die Zugangsdaten nicht. Daher werden die Tasks nicht erfolgreich gestartet.
Glücklicherweise hat Docker dafür einen Schalter vorgesehen, und zwar „--registry-auth„. Wird beim create-Kommando „--registry-auth“ angegeben, werden die Credentials an die einzelnen Nodes weiter gegeben, so dass der Download erfolgreich stattfinden kann. Ich habe dies auch erst später bemerkt und beim Update verwendet, die ersten Versuche bestanden darin, das Image einzeln auf jeden Node zu laden, was bei einer gewissen Anzahl von Nodes eher suboptimal ist.
Und sobald die Images vorhanden sind, werden sie auch erfolgreich gestartet:
geschke@tondi:~$ docker service tasks phpbackend ID NAME SERVICE IMAGE LAST STATE DESIRED STATE NODE 62ta97u1bryeacrr09x0ziyqu phpbackend.1 phpbackend hub.kuerbis.org:81/phptest Running 14 seconds ago Running lindenau 0b5fx2mjfkcrhsrrifafww1rf phpbackend.2 phpbackend hub.kuerbis.org:81/phptest Accepted 4 seconds ago Accepted tolkewitz 7l1tk47b3bygh8ijjc8f83og0 phpbackend.3 phpbackend hub.kuerbis.org:81/phptest Running 9 minutes ago Running tondi a4duhf5dyed6rri25wpum87vd phpbackend.4 phpbackend hub.kuerbis.org:81/phptest Running 15 seconds ago Running miltitz 4cjak7yqw7l655s4j8qns3hhc phpbackend.5 phpbackend hub.kuerbis.org:81/phptest Running 14 minutes ago Running connewitz
Ein Image für Nginx
Um die Funktionalität des PHP-FPM-Services grundsätzlich zu testen, wollte ich zunächst auf klassischem Wege per „docker run...“ einen Nginx-Container starten, der der zuvor angelegte Overlay-Network nutzt, um PHP-FPM auf Port 9000 zu erreichen. Auch für Nginx hatte ich mir vor einiger Zeit ein minimales Image gebaut, was auf Alpine Linux basiert, und mit dem es möglich ist, eine doch Ubuntu-ähnliche Konfiguration (Konfigurationsdateien für virtuelle Server in „sites-enabled“ etc.) zu verwenden. Dabei werden beim bisherigen Weg die Konfigurationsdateien als Volume zur Laufzeit in den Container gemountet.
Nach Anpassung der Konfigurationsdateien der erste Versuch:
geschke@connewitz:~/docker-nginx/files$ docker run -d --name nginx --restart=always -v /home/geschke/docker-nginx/sites-enabled:/etc/nginx/sites-enabled -v /home/geschke/docker-nginx/www:/var/www -v /home/geschke/docker-nginx/conf.d:/etc/nginx/conf.d --publish 80:80 --net=gnswarm geschke/nginx docker: Error response from daemon: swarm-scoped network (gnswarm) is not compatible with `docker create` or `docker run`. This network can only be used by a docker service. See 'docker run --help'.
Auf die klassische Art und Weise funktionierte dies also nicht. Insofern musste auch für Nginx bzw. dessen Konfiguration ein Image gebaut werden, was wiederum im privaten Repository Platz genommen hat.
Um es abzukürzen – die Konfiguration bestand aus einigen Versuchen per Trial-and-Error, hauptsächlich bedingt durch die jeweiligen Pfade, die bei Nginx und PHP-FPM verwendet werden. Nginx gibt z.B. die Angabe über das Document-Root-Verzeichnis an PHP-FPM weiter, so dass PHP seine Dateien darin finden kann. Denn sobald eine Datei mit der Endung „.php“ genutzt wird, kommt auch PHP zum Einsatz. Statische Dateien hingegen können im Nginx-Image Platz nehmen, von dort aus werden sie direkt von Nginx beim Request ausgeliefert.
Das Dockerfile von Nginx sieht letztlich wie folgt aus:
FROM geschke/nginx LABEL last_changed="2016-07-23" MAINTAINER Ralf Geschke <ralf@kuerbis.org> COPY files/nginx.conf /etc/nginx/ RUN mkdir -p /etc/nginx/sites-enabled && mkdir -p /var/www/html COPY files/sites-enabled/* /etc/nginx/sites-enabled/ COPY files/www/* /var/www/html/ EXPOSE 80 443 CMD ["nginx"]
Im Verzeichnis files/sites-enabled befindet sich eine Datei namens „default“, die nicht viel anders ist als die Standard-Konfiguration für einen virtuellen Host:
server {
listen 80;
server_name _;
root /var/www/html;
index index.php index.html index.htm;
location / {
# First attempt to serve request as file, then
# as directory, then fall back to displaying a 404.
try_files $uri $uri/ /index.php;
}
# pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000
#
location ~ \.php$ {
# # With php5-cgi alone:
fastcgi_pass phpbackend:9000;
# # With php5-fpm:
#fastcgi_pass unix:/var/run/php/php7.0-fpm.sock;
fastcgi_index index.php;
include fastcgi.conf;
}
}
Ebenfalls recht kurz gehalten ist die zentrale nginx.conf, die in das Image hinein kopiert wird:
# (Hinweis: Kommentare der Übersichtlichkeit halber entfernt)
worker_processes 4;
daemon off;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
gzip on;
gzip_disable "msie6";
include /etc/nginx/conf.d/*.conf;
include /etc/nginx/sites-enabled/*;
}
In dem „files/www/„-Verzeichnis befindet sich nur eine statische HTML-Datei, um die direkte Auslieferung von Nginx zu testen. Die PHP-Dateien hingegen sind im PHP-FPM-Image „phptest“ enthalten!
Also gebaut und gepusht:
geschke@connewitz:~/docker-nginx$ docker build -t nginxphp . [...] geschke@connewitz:~/docker-nginx$ docker tag nginxphp hub.kuerbis.org:81/nginxphp geschke@connewitz:~/docker-nginx$ docker pull hub.kuerbis.org:81/nginxphp
Bei einem weiteren Versuch wollte ich den Nginx-Service nur auf dem (lokalen) Node „connewitz“ starten. Dazu wurden so genannte Constraints genutzt, hier zur Einschränkung der Node-ID:
docker service create --name frontend -p 80:80/tcp --network gnswarm --constraint node.id==9r6mfzv4gflyafi9uwikaaqvf hub.kuerbis.org:81/nginxphp
Aus noch unbekannten Gründen war dies leider nicht erfolgreich, der Port 80 ließ sich auf dem betreffenden Node nicht ansprechen. Daher der neue Versuch, nun sollte Docker sich um die Verteilung der Tasks kümmern:
docker service create --name frontend -p 80:80/tcp --network gnswarm hub.kuerbis.org:81/nginxphp b196ddilz9d645imr20we4b7z geschke@connewitz:~/docker-nginx$ docker service ls ID NAME REPLICAS IMAGE COMMAND 9jxmteiyjk8k phpbackend 5/5 hub.kuerbis.org:81/phptest b196ddilz9d6 frontend 1/1 hub.kuerbis.org:81/nginxphp geschke@connewitz:~/docker-nginx$ docker service tasks frontend ID NAME SERVICE IMAGE LAST STATE DESIRED STATE NODE b8j84fl6ga2hvnhmtblegqvnf frontend.1 frontend hub.kuerbis.org:81/nginxphp Running 35 seconds ago Running miltitz
Der Task lief auf „miltitz“ – und tatsächlich war die „Anwendung“ nun auch erreichbar:
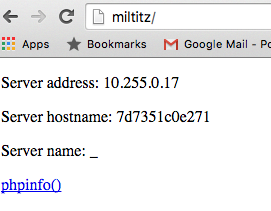
Und auch die anderen Nodes waren erreichbar, einzig wechselte wiederum der Hostname, je nach dem, auf welcher PHP-FPM-Instanz man sich befand bzw. von welchem Task der Request verarbeitet wurde. Grundsätzlich also sehr, sehr cool!
Auch das Hinzufügen weiterer Tasks war möglich, ebenso konnte die Anzahl wieder verringert werden usw.:
geschke@connewitz:~/docker-php-test$ docker service scale frontend=3 frontend scaled to 3 geschke@connewitz:~/docker-php-test$ docker service ls ID NAME REPLICAS IMAGE COMMAND 9jxmteiyjk8k phpbackend 5/5 hub.kuerbis.org:81/phptest b196ddilz9d6 frontend 3/3 hub.kuerbis.org:81/nginxphp
Load-Balancing per DNS-Round-Robin
Eine (sehr) einfache Möglichkeit der Lastverteilung kann z.B. per DNS Round Robin erfolgen. Dabei werden einem Hostnamen mehrere IP-Adressen zugeordnet. Die grundlegende Funktionsweise beschreibt Wikipedia sehr gut, im Beispiel hatte ich den lokalen DNS so konfiguriert, dass alle Nodes mittels des Namens „swarm“ ansprechbar sind:
swarm IN A 192.168.10.72 swarm IN A 192.168.10.73 swarm IN A 192.168.10.39 swarm IN A 192.168.10.64 swarm IN A 192.168.10.66 swarm IN A 192.168.10.65 swarm IN A 192.168.10.43
Bei der DNS-Abfrage wird dieser Name aufgelöst, und bei mehreren Anfragen wechselt die Reihenfolge.
geschke@connewitz:~$ dig swarm.geschke.net ; <<>> DiG 9.10.3-P4-Ubuntu <<>> swarm.geschke.net ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 59633 ;; flags: qr aa rd ra; QUERY: 1, ANSWER: 7, AUTHORITY: 2, ADDITIONAL: 3 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ;; QUESTION SECTION: ;swarm.geschke.net. IN A ;; ANSWER SECTION: swarm.geschke.net. 172800 IN A 192.168.10.43 swarm.geschke.net. 172800 IN A 192.168.10.39 swarm.geschke.net. 172800 IN A 192.168.10.73 swarm.geschke.net. 172800 IN A 192.168.10.72 swarm.geschke.net. 172800 IN A 192.168.10.65 swarm.geschke.net. 172800 IN A 192.168.10.64 swarm.geschke.net. 172800 IN A 192.168.10.66 [...]
Für wirkliche Ausfallsicherheit müsste nun noch der DNS-Server so konfiguriert werden, dass je nach Verfügbarkeit der Nodes die Konfiguration angepasst wird. Später…
Nachtrag – scale up and down
Als ich während des Schreibens dieses Artikels ein wenig die laufenden Services modifiziert habe, d.h. die Anzahl der Tasks verringert, wieder erhöht usw., zeigte sich eine zeitweise Instabilität. So wurden bei manchen Nodes 502 „Bad gateway“-Fehler angezeigt, andere antworteten gar nicht. In der Netzwerk-Konfiguration von Docker bzw. den Services fand ich nichts Ungewöhnliches („docker service inspect <service>“), und bis zur Analyse der Logfiles bin ich währenddessen nicht gekommen. Die genaue Ursache gilt es somit noch, herauszufinden, denn natürlich darf die erwünschte Eigenschaft der Ausfallsicherheit nicht zu Lasten der Stabilität gehen. Insofern bleibt noch einiger Raum für Analysen und Experimente…
Fazit
Grundsätzlich sind die Docker Services ein sehr gutes Feature, insbesondere das Load-Balancing, sofern es denn funktioniert, bietet eine relativ einfach konfigurierbare Lösung zur Herstellung von Ausfallsicherheit. Ich beziehe mich hier tatsächlich auf Ausfallsicherheit und nicht auf Skalierbarkeit. Denn um Letztere zu erreichen, müssen alle Systemkomponenten darauf ausgelegt sein, was jedoch nicht mit einem einzelnen „scale“-Kommando auf einer fest stehenden Anzahl von Nodes erreicht wird. Zwar können Nodes auch relativ einfach hinzugefügt werden, womit wiederum eine horizontale Skalierung erreicht würde, aber dazu muss erst einmal die entsprechende Infrastruktur bereit stehen.
Betrachtet man jedoch ein mit Docker Services aufgebautes System, was aus mehreren Nodes besteht, ist eine gewisse Ausfallsicherheit gegeben. Fälle ein Node aus, sorgt Docker dafür, dass die Tasks auf die noch vorhandenen Nodes verteilt werden.
Die Images müssen jedoch für den Betrieb als Service von vornherein ausgelegt sein. In diesem Sinn sind die Tasks der Services ein shared-nothing-System, sie kennen keinen gemeinsamen Speicherbereich, haben keinen Zugriff auf ein gemeinsames Dateisystem und müssen auch unabhängig voneinander in derselben Konfiguration lauffähig sein. Die Konfiguration muss daher ebenfalls entweder direkt in das Image gepackt werden oder als Umgebungsvariable mittels --env-Parameter übergeben werden können.
Dies wird bereits bei einfachen Features von Web-Anwendungen wie Uploads von Bildern etc. zu einer Herausforderung, auf die die Anwendung angepasst werden muss. Die Speicherung im Filesystem verbietet sich, insofern müsste ein gemeinsamer Speicher bzw. -Dienst wie AWS S3 genutzt werden, oder z.B. GridFS von MongoDB. Überhaupt stellen Datenbanken eine weitere Herausforderung dar. Dies beginnt bereits bei der Konfiguration, denn für den Aufbau etwa eines MariaDB-Galera-Clusters muss ein Image vorhanden sein, was von Initialisierung bis zu Betrieb einwandfrei ist, und wo sollen überhaupt die Daten gespeichert werden – verteiltes Dateisystem – oder doch besser auf Docker in diesem Umfeld verzichten? Und man muss ja auch nicht alles „dockerisieren“. Bei MongoDB funktioniert dies zwar auf dem klassischen Weg recht gut, aber auch das setzt einige Vorab-Konfiguration voraus. Und nicht zuletzt liegen die Daten auf den Hosts, von denen die Volumes in die Container gemountet werden. Um diese von einem Service-Task zu erreichen, müsste es jedoch ein gemeinsames Netz geben, oder man müsste mittels Firewall wiederum nur den Zugriff von außen verbieten…
Insofern – insgesamt gibt es noch etliche Baustellen, noch sind nicht alle Probleme gelöst oder Herausforderungen bewältigt. Und nicht zu vergessen, aktuell (Stand 25.07.2016) ist Docker 1.12 mit diesen neuen Features ja auch noch Release Candidate…




Danke für den Artikel!
Ich beschäftige mich gerade genau mit dem Thema, da ich demnächst eine wohl sehr schnell waschsende Online Plattform betreiben werde.