
Nach den Erkenntnissen aus der näheren Betrachtung der Logs und der im letzten Artikel beschriebenen Sperrung von unerwünschten Besuchern war meine Neugier geweckt worden. Zwar werden die komplett sinnlosen Anfragen von Traefik problemlos verarbeitet und laufen letztlich ins Leere, aber mir schwebte dennoch eine umfassendere Lösung vor, die es ermöglichen würde, nicht nur zufällig den einen oder anderen Störenfried zu entdecken, sondern systematisch und konsequent, um ggf. in einem nächsten Schritt weitere Gegenmaßnahmen einleiten zu können.
Logging zentral
Meine Idee war, dass alle Logs der jeweiligen Docker-Container auf allen Servern an zentraler Stelle gesammelt würden, insbesondere natürlich von den Traefik-Containern, um eine einfache Darstellung und Auswertung zu ermöglichen, ohne auf die einzelnen Hosts oder gar Docker-Container zugreifen zu müssen. Natürlich sollte alles mit Open-Source-Tools realisiert werden können, und wie bei mir inzwischen üblich mit Hilfe von Docker. Für die Sammlung und Auswertung der Logs hatte ich mir eine der VMs auserkoren, die ich in freier Wildbahn betreibe, somit war die Einrichtung entsprechender Authentifizierungsmethoden unerlässlich.
Tool-Suche einmal anders
Die normalerweise per Google-Suche zu Beginn durchgeführte Recherche überließ ich diesmal jedoch ChatGPT. Nach Nennung der Anforderungen sollte mir ChatGPT eine sinnvolle Lösung vorschlagen und daran anschließend Hinweise zur Konfiguration liefern. Das klappte insgesamt – naja, sagen wir mal semi-gut. Und natürlich muss ich kaum erwähnen, dass ich nicht „blind“ alles übernommen habe, was mir die Maschine vorgeschlagen hat, eher im Gegenteil. Tatsächlich verlief der Prozess der Installation diesmal jedoch ein wenig anders als zuvor.
Während ich ansonsten zunächst Quellen wie Web-Sites der Tools, Dokumentations-Seiten, Blog-Einträge zum Thema, Artikel aus Zeitschriften etc. gesammelt und ausgewertet hatte, um daraus eine eigene Lösung zu adaptieren, und dabei eine Art „Installations-Log“, also eine Mitschrift der ausgeführten Schritte geführt habe, habe ich nun mehr mit ChatGPT kommuniziert und vieles ausprobiert, ohne alle einzelnen Schritte nochmal extra zu notieren. Die folgende Anleitung konzentriert sich somit mehr auf die Ergebnisse als auf den eigentlichen Installationsprozess, wobei ich mir auch dazu einige Anmerkungen nicht sparen werde.
Zunächst schlug mit ChatGPT zwei mögliche Lösungen vor, von denen eine aus den Tools Loki, Promtail und Grafana bestand. Über die zweite hülle ich mal lieber den Mantel des Schweigens, da mir diese wie eine Reminiszenz meiner Linux-Anfänge vorgekommen war.
Ein Blick auf die jeweiligen Web-Seiten der Tools förderte jedoch zutage, dass das Tool Promtail auch nicht gerade knackfrisch war, denn laut dessen Entwickler Grafana Labs war es inzwischen als veraltet gekennzeichnet und würde die End-of-Life-Phase in ungefähr einem Jahr erreichen. Doch heute mit einem Tool zu starten, dessen Ende bereits besiegelt bzw. geplant ist, erschien mir als eher schlechte Idee. Damit hätte die nächste Migration bereits an der Tür geklopft, also schaute ich mir lieber die Empfehlung von Grafana Labs in Form des Tools Alloy an.
Alloy, Loki und Grafana aus der Vogelperspektive
Ein kurzer Überblick: Grafana Alloy ist ein Open-Source-Tool zur Erfassung, Verarbeitung und Weiterleitung von Logs, Metriken und Traces. Ob man es nun „OpenTelemetry Collector„, „modularer Observability-Agent„, „Telemetry-Pipeline“ oder gar „Observability Data Pipeline Tool“ nennen möchte, sei jedem selbst überlassen. Im Kern ist Alloy ein Tool, das Daten (Logs, Metriken) aus unterschiedlichen Quellen sammelt bzw. empfängt, verarbeitet und an wiederum unterschiedliche Empfänger versenden kann.
Einer dieser Empfänger stammt dabei ebenfalls aus dem Hause Grafana Labs und hört auf den Namen Loki. Loki ist ein Open-Source-Log-Analyzer, oder auch Log-Aggregations-System, insofern ein Tool, das sich für die effiziente Sammlung, Speicherung und Analyse von Logdaten zuständig zeigt. Dabei speichert Loki die Logs im Gegensatz zu klassischen Log-Systemen wie Elasticsearch (ELK-Stack), Graylog oder Splunk nicht als durchsuchbaren Text, sondern indiziert die Metadaten als Set von Labels, was ressourcenschonender sein soll.
Zur Visualisierung und Analyse dient wiederum das bereits aus früheren Artikel bekannte Tool Grafana, das eine web-basierte Oberfläche zum Erstellen interaktiver Dashboards bietet und eine Vielzahl von Datenquellen unterstützt. So zum Beispiel die Zeitreihen-Datenbank Prometheus, aber eben auch Loki. Das folgende Diagramm bietet eine Übersicht der geplanten Struktur in der endgültigen Ausbaustufe:
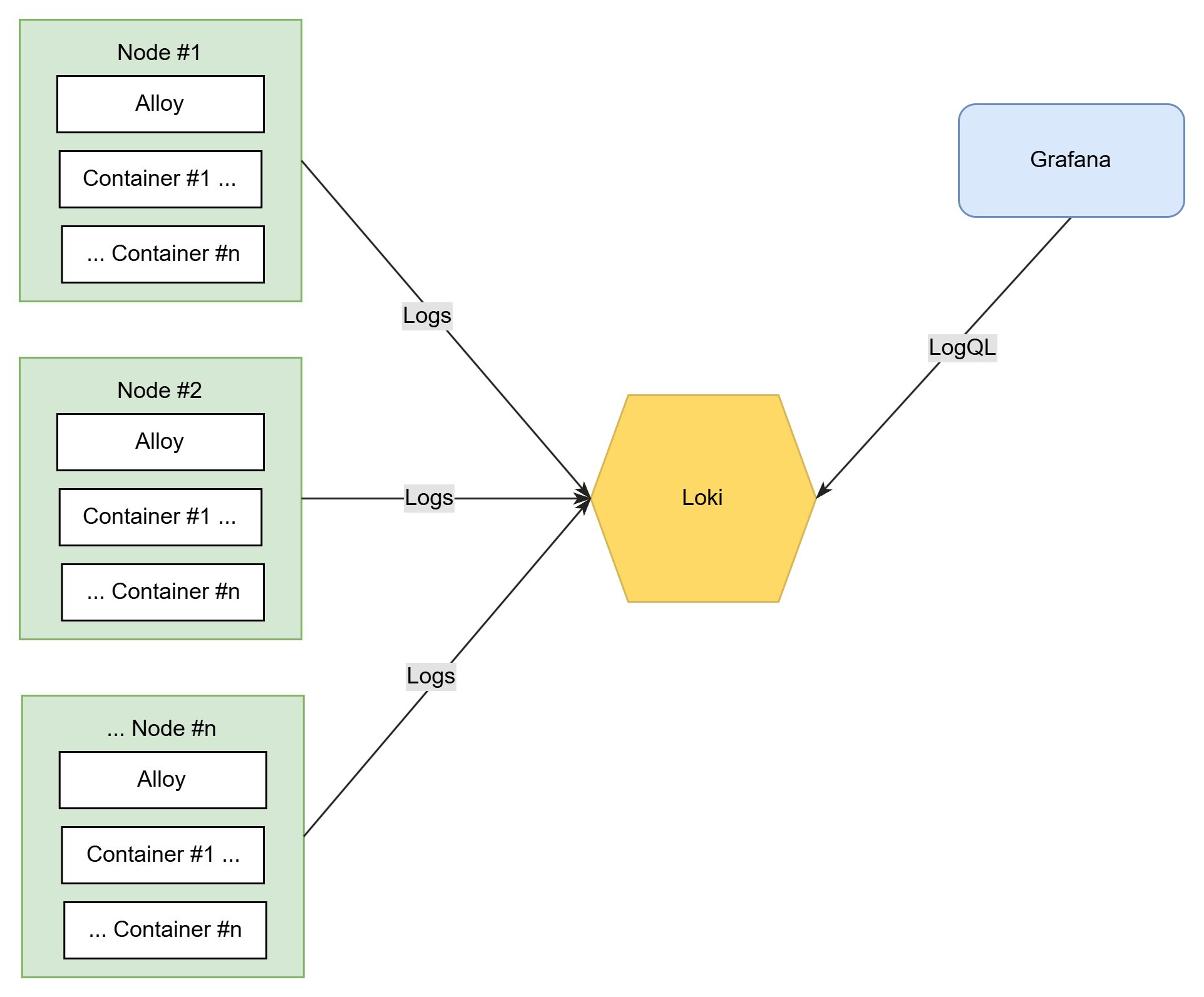
Ohne Docker läuft (hier) nichts
Auf allen Nodes, d.h. VMs, sind Docker-Container für unterschiedliche Zwecke im Einsatz. Von diesen sammelt Alloy die entsprechenden Logs und gibt sie weiter an Loki. Loki wiederum speichert alle Logs an zentraler Stelle und dient als Datenquelle für Grafana. Dass sich Grafana sowie Loki wiederum als Docker-Container auf einem der Nodes befinden, ist in dieser Darstellung außen vor gelassen.
Da sich alles „da draußen“ in freier Internet-Wildbahn und nicht in einem privaten und geschützten Netz abspielt, muss zudem sämtlicher Datenverkehr verschlüsselt und authentifiziert erfolgen. Hierbei spielt der Traefik-Proxy die entscheidende Rolle, der als Instanz vor den jeweiligen Diensten steht, so dass von außen weder Loki, noch Grafana direkt erreichbar sind, sondern nur über verschlüsselte https-Verbindungen nach Authentifizierung. Alloy hingegen sendet nur seine Daten, dient somit nicht als Server für andere Dienste bzw. öffnet seinen Port nur für localhost – dazu später mehr.
Installation #1: Loki
Und natürlich sollten alle genannten Tools als Docker-Container mit Docker Compose eingerichtet werden. Da Alloy ohne vorhandenen Empfänger, in diesem Fall ohne Loki reichlich sinnfrei ist, starte ich mit der Installation und Einrichtung von Loki.
Zunächst das entsprechende Docker-Compose-File:
services:
loki:
image: grafana/loki:3.5
container_name: loki
restart: unless-stopped
volumes:
- ./loki/config.yaml:/etc/loki/config.yaml:ro
- ./loki/data:/loki
labels:
- "traefik.enable=true"
- "traefik.docker.network=traefik-public"
- "traefik.constraint-label=traefik-public"
- "traefik.http.routers.loki.rule=Host(`logs.xyzcdn.xyz`)"
- "traefik.http.routers.loki.entrypoints=http"
- "traefik.http.middlewares.loki.redirectscheme.scheme=https"
- "traefik.http.middlewares.loki.redirectscheme.permanent=true"
- "traefik.http.routers.loki.middlewares=https-redirect"
- "traefik.http.routers.loki-secured.rule=Host(`logs.xyzcdn.xyz`)"
- "traefik.http.routers.loki-secured.entrypoints=https"
- "traefik.http.routers.loki-secured.tls.certresolver=le-tls"
- "traefik.http.services.loki-secured.loadbalancer.server.port=3100"
- "traefik.http.routers.loki-secured.middlewares=secHeaders@file,loki-mwlogin,def-compress@file"
- "traefik.http.routers.loki-secured.priority=1"
- "traefik.http.middlewares.loki-mwlogin.basicauth.users=lokiuser:lokipassword"
networks:
- traefik-public
networks:
traefik-public:
external: true
Da letztlich allen nervtötenden Bots und sonstigen Unholden der Hostname gefühlt drei Sekunden nach der Einrichtung im DNS bekannt war, verzichte ich hier auf fiktive Domains wie „example.com“ oder ähnlichen. Traefik sorgt hier zum einen für die Einrichtung des Let’s-Encrypt-Zertifikats für den gewählten Hostnamen und somit für verschlüsselte Kommunikation, und sichert zum anderen alles per HTTP-Basic-Authentication ab. Den Vorgang zur Einrichtung selbiger inklusive des Passworts hatte ich bereits im Artikel zum Aussperren unerwünschter Besucher beschrieben, weshalb ich hier nicht weiter darauf eingehe. Ansonsten befinden sich im Compose-File keine größeren Überraschungen, alle Requests werden an den Port 3100 und somit Loki weitergeleitet.
Konfiguration Loki
Die eigentliche Konfiguration von Loki ist in der Datei ./loki/config.yaml zu finden, die in den Container gemappt wird, außerdem wird das Verzeichnis zur Speicherung der Daten ./loki/data zur Verfügung gestellt.
Diese Konfigurationsdatei ./loki/config.yaml sieht in der aktuellen Fassung bei mir wie folgt aus:
server:
http_listen_port: 3100
grpc_listen_port: 9095
auth_enabled: false
common:
path_prefix: /loki
storage:
filesystem:
directory: /loki/data
replication_factor: 1
ingester:
chunk_idle_period: 5m
chunk_retain_period: 30s
max_transfer_retries: 0
schema:
configs:
- from: 2024-01-01
index:
period: 24h
prefix: index_
object_store: filesystem
schema: v12
store: tsdb
limits:
retention_period: 8760h # 365 Tage
reject_old_samples: false
reject_old_samples_max_age: 672h
compactor:
working_directory: /loki/compactor
shared_store: filesystem
retention_enabled: true
Hier hat ChatGPT tatsächlich recht gute Arbeit geleistet und mir diese Datei so aufgebaut, offizielle Beispiele aus dem Getting-Started-Guide sind darüber hinaus auf GitHub im Examples-Verzeichnis zu finden.
Der hier geöffnete Port 3100 ist beim Betrieb als Docker-Container nur innerhalb des Docker-Netzes erreichbar, Traefik sorgt für alles Weitere, daher ist eine eigene Authentifizierung hier nicht notwendig.
Die Retention Period, also die Zeit, wie lange Logs gespeichert bleiben, war im ersten Beispiel zunächst auf „168h“, also sieben Tage gesetzt. Danach wären alle Logs vom sog. Compactor gelöscht worden („retention_enabled: true„). Da mir diese Zeitspanne doch ein wenig kurz erschien, und da der Speicherplatz noch lange nicht knapp ist, habe ich sie zu Testzwecken auf ein Jahr gesetzt. In der Praxis würde man hier jedoch einen kürzeren Zeitraum einsetzen, ganz nach Belieben und Speicherplatz-Limit. Langzeit-Reports bzw. Metriken statt Logs ließen sich diese dann für andere Systeme exportieren.
Damit könnte Loki wie üblich mit Docker Compose gestartet werden, doch beim ersten Versuch gab es noch Probleme mit Zugriffsrechten. Loki läuft unter der User-ID 10001 und erwartet genau diese User-ID für seine Verzeichnisse. Insofern genügt es, die Rechte entsprechend einzurichten:
sudo chown -R 10001:10001 ./loki
Danach kann Loki gestartet werden:
geschke@stralsund:~/services/loki$ docker compose -f docker-compose-loki.yml up -d
Zum Testen kann beispielsweise die API abgefragt werden, im Folgenden werden die Labels ausgelesen:
curl -u lokiuser:lokipassword https://logs.xyzcdn.xyz/loki/api/v1/labels --insecure
Das Flag --insecure ist nur notwendig, wenn das TLS-Zertifikat noch self-signed ist, in meinem Beispiel konnte es problemlos weg gelassen werden, da Traefik bereits für echte Let’s-Encrypt-Zertifikate gesorgt hat. Loki sollte dann etwas antworten wie:
{"status":"success","data":["filename","job","instance",...]}
Alternativ kann auch die URL „https://logs.xyzcdn.xyz/ready“ per Browser aufgerufen werden, dort sollte Loki mit der Ausgabe von „ready“ antworten.
Der Pfad „/metrics“ bietet übrigens Prometheus-kompatible Metriken, die zur Überwachung von Loki selbst wiederum an Prometheus angebunden werden können.
Installation #2: Alloy
Damit wäre Loki betriebsbereit installiert, weshalb nun das zweite Tool an der Reihe ist, und zwar Alloy. Dazu möchte ich vorab erwähnen, dass die folgenden Konfigurationsdateien das Ergebnis von einigen Trial-and-Error-Iterationen sind. Denn zunächst hatte ich noch versucht, Alloy nicht nur für die Sammlung von Docker-Logs, sondern auch für die Systemüberwachung einzusetzen. Diesen Job übernimmt aber auch weiterhin der bereits eingesetzte Node Exporter, mehr dazu am Ende dieses Artikels.
Zunächst das Docker-Compose-File von Alloy:
services:
alloy:
image: grafana/alloy:v1.8.2
container_name: alloy
restart: unless-stopped
command: run --server.http.listen-addr=0.0.0.0:12345 /etc/alloy/config.alloy
ports:
- 127.0.0.1:12345:12345
volumes:
- /var/run/docker.sock:/var/run/docker.sock:ro
- /var/lib/docker/containers:/var/lib/docker/containers:ro
- ./alloy/config.alloy:/etc/alloy/config.alloy:ro
- ./data:/data-alloy
- ./geoip:/etc/geoip
environment:
- HOSTNAME=${HOSTNAME:-$(hostname)}
Alloy besitzt auch eine Server-Komponente, die hier jedoch nur lokal, d.h. auf localhost bzw. dessen IP-Adresse verfügbar ist. Damit können rudimentäre Verwaltungstätigkeiten ausgeführt wie z.B. ein Reload initiiert werden. Insofern wird dieser Server auf Port 12345 (kein Witz!) auch nicht für die gesamte Welt nach außen freigegeben, Traefik ist somit hier nicht im Spiel.
Die Verzeichnisstruktur ist reichlich simpel, unter ./alloy/ befindet sich die eigentliche Alloy-Konfigurationsdatei namens config.alloy, daneben werden im Verzeichnis ./geoip die MaxMind-GeoIP-Datenbanken zur Verfügung gestellt. Dies ist zwar optional, aber da die GeoIP-„Lite“-Fassungen kostenlos zur Verfügung gestellt werden, und mir die jeweils zugreifenden Länder oder Regionen insbesondere bei Web-Server-Logs durchaus interessant erschienen, habe ich die Nutzung der GeoIP-Daten entsprechend konfiguriert.
Zur Speicherung von internen Daten der verwendeten Komponenten, z.B. Positionsangaben, dient standardmäßig der Pfad /data-alloy/. Dies kann zwar geändert werden mittels Start-Parameter „--storage.path„, aber hier soll der Standard beibehalten werden. Da Alloy in einem Docker-Container läuft, wird ein Verzeichnis ./data in den Container gemountet, so dass Alloy beim Neustart des Containers darauf zurückgreifen kann.
Konfiguration Alloy
Die bei mir aktuell laufende Fassung der Datei ./alloy/config.alloy sieht wie folgt aus:
discovery.docker "default" {
host = "unix:///var/run/docker.sock"
}
discovery.relabel "logs_integrations_docker" {
targets = []
rule {
source_labels = ["__meta_docker_container_name"]
regex = "/(.*)"
target_label = "container_name"
}
// --- Drop unwanted containers ---
rule {
source_labels = ["container_name"]
regex = ".*(alloy|grafana|loki).*"
action = "drop"
}
// --- End drop rules ---
rule {
source_labels = ["__meta_docker_container_label_com_docker_compose_service"]
target_label = "compose_service"
}
rule {
source_labels = ["__meta_docker_container_label_com_docker_compose_project"]
target_label = "compose_project"
}
}
loki.source.docker "default" {
host = "unix:///var/run/docker.sock"
targets = discovery.docker.default.targets
labels = {"host" = "stralsund","platform" = "docker"}
relabel_rules = discovery.relabel.logs_integrations_docker.rules
forward_to = [loki.process.filter_logs.receiver]
//forward_to = [loki.write.default.receiver]
}
// --- Process and drop unwanted logs ---
loki.process "filter_logs" {
stage.drop {
expression = ".*(loki-secured@docker|prometheus@internal|grafana@docker|dashboard@internal|api@internal|node_exporter-01-secured@docker).*"
}
forward_to = [loki.process.get_geoip_data.receiver]
}
loki.process "get_geoip_data" {
stage.regex {
expression = "^(?P<remote_ip>\\d+\\.\\d+\\.\\d+\\.\\d+)"
}
stage.geoip {
source = "remote_ip"
db = "/etc/geoip/GeoLite2-City.mmdb"
db_type = "city"
}
stage.labels {
values = {
geoip_city_name = "",
geoip_country_name = "",
geoip_country_code = "",
geoip_continent_name = "",
geoip_continent_code = "",
//geoip_location_latitude = "",
//geoip_location_longitude = "",
//geoip_postal_code = "",
geoip_timezone = "",
geoip_subdivision_name = "",
geoip_subdivision_code = "",
}
}
forward_to = [loki.write.default.receiver]
}
loki.write "default" {
endpoint {
url = "https://logs.xyzcdn.xyz/loki/api/v1/push"
basic_auth {
username = "lokiuser"
password = "lokipassword"
}
}
}
Die Datei orientiert sich weitestgehend an den Beispielen aus der Alloy-Dokumentation. Die discovery.docker-Komponente erkennt Docker-Container und extrahiert Metadaten anhand des Docker-Sockets, der in den Alloy-Container gemountet wurde. Dies ist die einfachste Art der Konfiguration, weitere Möglichkeiten finden sich ebenfalls in der Alloy-Dokumentation.
Die discovery.relabel-Komponente definiert Regeln zur Umbenennung, um einen Dienst-Namen aus einem Container-Namen zu erstellen. In der ersten Regel wird beispielsweise aus der etwas sperrigen Angabe __meta_docker_container_name die Bezeichnung container_name, wobei der reguläre Ausdruck den führenden Slash („/“) aus dem Namen entfernt.
Die letzten beiden Regeln in diesem Abschnitt sorgen analog dafür, dass die Labels compose_service und compose_projekt aus den entsprechenden Angaben erzeugt werden. Eine weitere Regel, in diesem Beispiel die zweite im Abschnitt, verwirft („drop„) bestimmte Container, und zwar diejenigen, bei denen „alloy„, „loki“ oder „grafana“ im Namen zu finden sind. Dies soll dafür sorgen, dass die „eigenen“ Container keine weitere Betrachtung finden.
Mit „loki.source.docker“ wird schließlich die Komponente definiert, die Logs von Docker-Containern sammelt. Dabei wird bei „host“ wieder der Docker-Socket angegeben, in „targets“ finde sich die Liste der Container, von denen die Logs gelesen werden sollen. Bei „labels“ ist der Hostname des betreffenden Servers angegeben, außerdem als „platform“ der Hinweis auf Docker. Hierbei handelt es sich um den Standard-Satz von Labels, der auf die Log-Einträge angewendet wird. In den „relabel_rules“ werden schließlich die Regeln zur Umbenennung angegeben, die zuvor definiert wurden. Zuletzt folgt mit „forward_to“ der Empfänger der Einträge.
Das gesamte Konstrukt kann man sich wie eine Pipe unter Linux vorstellen, bzw. allgemein wie eine Pipeline, in die zu Beginn irgendetwas hinein gekippt wird, und am Ende wiederum irgendetwas heraus kommt. Zwischendurch können optionale Bearbeitungsschritte enthalten sein, die die Einträge verändern, Daten hinzufügen, entfernen o.ä..
Im Beispiel folgt im nächsten Schritt der Empfänger namens „filter_logs„, der nachfolgend definiert wird. Hier werden durch „stage.drop“ die darin bezeichneten Traefik-Services ausgeschlossen bzw. einfach entfernt. Auch dies dient zur Verringerung der Menge von Log-Daten. Da ansonsten jeglicher Zugriff auf interne oder irrelevante Services von Traefik ebenfalls einen Eintrag bei Loki verursachen würde, werden diese Einträge an dieser Stelle nicht weiter gelassen. Anschließend werden die Daten an den Empfänger „get_geoip_data“ weitergeleitet.
In diesem Loki-Prozess, der wiederum im nächsten Abschnitt definiert wird, passiert nun Folgendes: Zunächst wird aus den empfangenen Daten die IPv4-Adresse im Stage „stage.regex“ mittels eines regulären Ausdrucks extrahiert, diese steht anschließend in der Variable „remote_ip“ zur Verfügung. Im Bereich „stage.geoip“ kommt schließlich die GeoIP-Datenbank zum Einsatz, anhand der IP-Adresse erfolgt die Abfrage nach den GeoIP-Daten. Dazu wird das Datenbank-File der GeoIP-Lite-Datenbank für die Städte benutzt, das sich im Verzeichnis /etc/geoip des Alloy-Containers befindet bzw. dort hinein gemountet wurde.
Im Bereich „stage.labels“ wird angegeben, mit welchen Labels die Logs angereichert werden sollen. Vielleicht auf den ersten Blick etwas missverständlich, aber tatsächlich bedeutet z.B. ‚geoip_city_name = ""‚ (also leere Zeichenkette), dass dieses Label mit den Daten aus dem GeoIP-Stage gefüllt werden soll.
Im Gegensatz dazu werden Labels, die hier nicht genannt werden, auch nicht berücksichtigt. So sind drei mögliche Labels nur als Kommentar vorhanden, diese könnten zwar mit Daten gefüllt werden, aber sie erschienen mir für die weitere Nutzung nicht unbedingt sinnvoll, weshalb ich sie ausgeschlossen habe. Außerdem darf nicht vergessen werden, dass zu viele Labels mit unterschiedlichen Werten in der weiteren Verarbeitung problematisch werden könnten, da alle Labels von Loki indiziert werden, was die Menge der zu speichernden Daten wiederum weiter erhöht.
Zuletzt werden sie so aufbereiteten Daten zum Empfänger namens „default“ weiter geleitet. Darin befindet sich nun endlich die URL der API von Loki als „endpoint„, außerdem werden hier noch die Zugangsdaten der Basic-Authentication angegeben. Nach diesem Schritt ist der Prozess auch abgeschlossen, d.h. Alloy hat alle Logs aus den betreffenden Docker-Containern gesammelt, einige entfernt, den Rest aufbereitet und zu Loki geliefert.
Wie leicht zu erkennen ist, sind die Möglichkeiten von Alloy sehr umfassend, natürlich können nicht nur Logs aus Docker, sondern Logs und Metriken von einer Vielzahl von Quellen verwendet und an unterschiedliche Ziele geliefert werden, schließlich versteht sich Alloy als „Big Tent“-Collector.
Wie üblich wird auch Alloy per Docker-Compose-Kommando gestartet:
geschke@stralsund:~/services/alloy$ docker compose -f docker-compose-alloy.yml up -d
Installation #3: Grafana
Um die von Alloy gesammelten Logs zu betrachten, fehlt noch eine Komponente, in diesem Fall das bekannte Open-Source-Tool zur Visualisierung von Metriken, Logs und Traces namens Grafana.
Hierbei ist keine umfangreiche Konfiguration notwendig, da sich Grafana komplett über seine webbasierte Oberfläche einrichten lässt. Insofern werden nur ein paar essenzielle Daten wie Username und Passwort des initialen Admin-Users im Docker-Compose-File definiert, alles andere erfolgt schließlich über die GUI.
Das Docker-Compose-File sieht bei mir aktuell wie folgt aus:
services:
grafana:
image: grafana/grafana-oss:latest
container_name: grafana
restart: always
environment:
- GF_SECURITY_ADMIN_USER=${GRAFANA_USER}
- GF_SECURITY_ADMIN_PASSWORD=${GRAFANA_PASSWORD}
- GF_SERVER_ROOT_URL=https://stats.xyzcdn.xyz/
volumes:
- ./grafana-data:/var/lib/grafana
networks:
- traefik-public
labels:
- "traefik.enable=true"
- "traefik.docker.network=traefik-public"
# Router für HTTPS
- "traefik.http.routers.grafana.rule=Host(`stats.xyzcdn.xyz`)"
- "traefik.http.routers.grafana.entrypoints=https"
- "traefik.http.routers.grafana.tls=true"
- "traefik.http.routers.grafana.tls.certresolver=le-tls"
- "traefik.http.routers.grafana.middlewares=grafana-auth"
# Service-Port
- "traefik.http.services.grafana.loadbalancer.server.port=3000"
# Middleware: Basic Auth
- "traefik.http.middlewares.grafana-auth.basicauth.users=grafanaadmin:grafanauser"
networks:
traefik-public:
external: true
Der Aufbau dürfte bereits bekannt sein, auch kommt hier die HTTP-Basic-Authentication zum Einsatz, wofür erneut mit htpasswd- oder openssl-Kommando das entsprechende Passwort generiert werden muss. Die Basic-Authentication dient damit als erste Hürde bzw. einfach Schutz vor unerwünschten Besuchern und deren Einstiegsversuchen in die Grafana-UI.
Am Rande sei bemerkt, dass sich Grafana – aus welchen Gründen auch immer – im Betrieb ein wenig zickig gezeigt hat bzgl. der vorgeschalteten Basic-Authentication. Eigentlich sollte die Sitzung beibehalten werden, solange der Browser nicht geschlossen wird, doch tatsächlich kam es vor, dass das Login-Fenster der Basic-Authentication plötzlich auftauchte und einen neuen Login verlangte. Nach der Ursache habe ich bislang noch nicht gesucht, nach dem erneuten Login funktionierte auch alles wie gehabt, aber es empfiehlt sich tatsächlich, die Eingaben bei Grafana, etwa bei Erstellung eines Dashboards, öfter zwischenzuspeichern, denn nach dem Reload waren die nicht gespeicherten Änderungen leider auch irgendwo in den Weiten des Web verschwunden.
Als Daten-Verzeichnis soll Grafana „./grafana-data“ nutzen, das in den Container gemountet wird. Da Traefik wiederum als Proxy dient, ist die Angabe des Traefik-Netzwerks notwendig, außerdem natürlich die üblichen Konfigurationsoptionen.
Die initialen User- und Passwort-Daten für Grafana, die beim Login in dessen UI benötigt werden, werden per Environment-Variablen übergeben. Da hierzu die Daten im Klartext notwendig sind, habe ich die Nutzung einer .env-Datei vorgezogen. Docker liest die Datei „.env“ einfach beim Start per Docker Compose ein und stellt sie in den darin angegebenen Variablen zur Verfügung. Der Aufbau ist denkbar einfach:
GRAFANA_USER=adminuser GRAFANA_PASSWORD=ganzTollesAdminPasswort
Vor dem Start fehlt noch eine Kleinigkeit – Grafana verlangt für sein Daten-Verzeichnis standardmäßig die User- und Gruppen-IDs 472, ansonsten bricht der Start mit einer „permission denied„-Fehlermeldung ab. Falls das Verzeichnis noch nicht existiert, sollte es angelegt und seine Rechte entsprechend angepasst werden:
mkdir -p ./grafana-data sudo chown -R 472:472 ./grafana-data
Dann kann auch endlich Grafana wie üblich per Docker Compose gestartet werden:
geschke@stralsund:~/services/grafana$ docker compose -f docker-compose-grafana.yml up -d
Nach kurzer Zeit sollte Grafana unter dem gewählten Hostnamen erreichbar sein – in meinem Fall unter „stats.xyzcdn.xyz„. Falls nicht, hilft ein Blick in die Traefik-UI. Nach dem ersten Login per Basic-Authentication taucht der Grafana-eigene Login auf, und man befindet sich direkt in einer beim ersten Start ziemlich leeren Benutzeroberfläche.
Grafana: Konfiguration und erste Schritte
Grafana kann zahlreiche Datenquellen einbinden. Deren Konfiguration wird unter „Connections“ -> „Data sources“ vorgenommen. Per Klick auf „Add new data source“ kann „Loki“ ausgewählt werden, wonach man auf die eigentliche Einstellungs-Seite geleitet wird, die je nach Grafana-Version ähnlich wie im folgenden Screenshot aussehen dürfte:
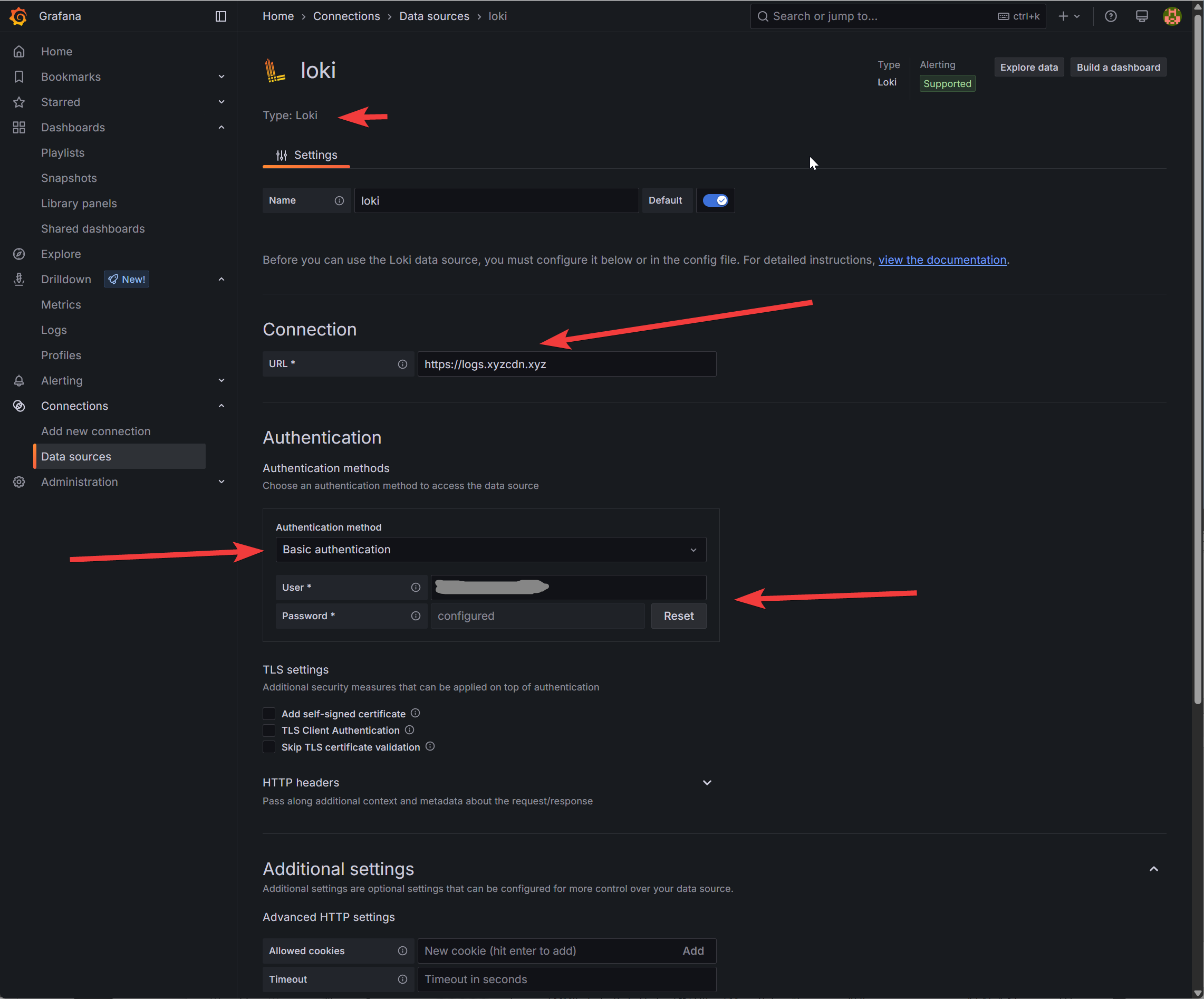
Der Typ „Loki“ ist bereits vorgegeben, so dass nur noch die URL des Loki-Servers und die Art der Authentifizierung ausgewählt werden müssen. Bei Wahl von „Basic authentication“ werden die Felder für User und Passwort angezeigt, hier sind einfach die bei Loki gewählten Angaben einzutragen. Am Ende der Seite befindet sich der Button „Save & test“ – und falls Grafana nach diesem Schritt nichts zu meckern hat, herzlichen Glückwunsch, auch diese Hürde wäre geschafft.
Für einen ersten Test, ob überhaupt Logs bei Loki eintrudeln, kann der Menüpunkt „Explore“ verwendet werden:
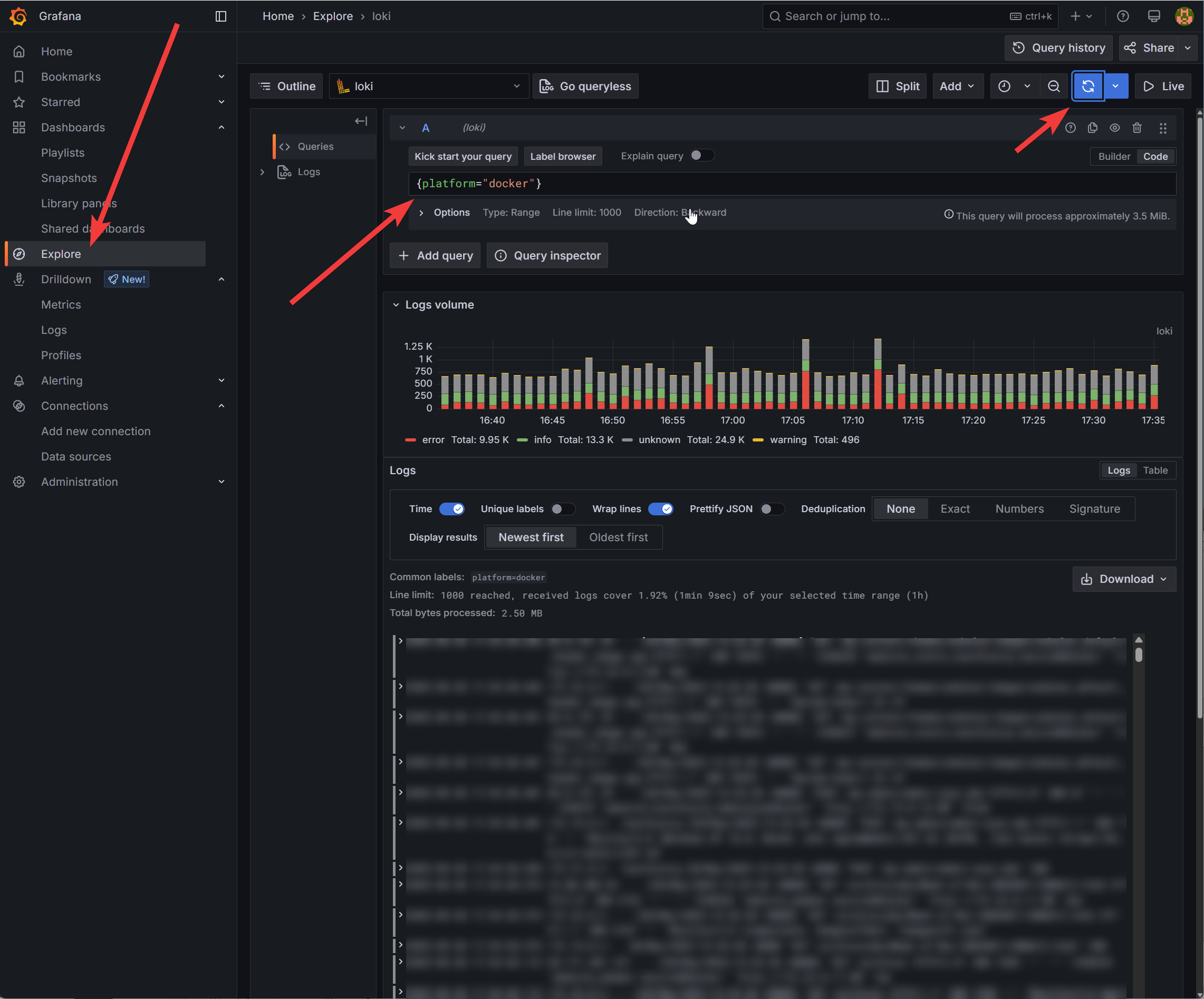
Eine sehr einfache Abfrage lautet beispielsweise ‚{platform="docker"}‚. Da es genaugenommen nur einen Wert für „platform“ gibt, da dieses Label fest in der Alloy-Konfigurationsdatei definiert wurde, tauchen bei dieser Query tatsächlich alle vorhandenen Logs auf – je nach System können dies durchaus eine ganze Menge sein.
Eine etwas bequemere Möglichkeit ist die Nutzung des „Label Browsers„, der ebenfalls unter „Explore“ zu finden ist:
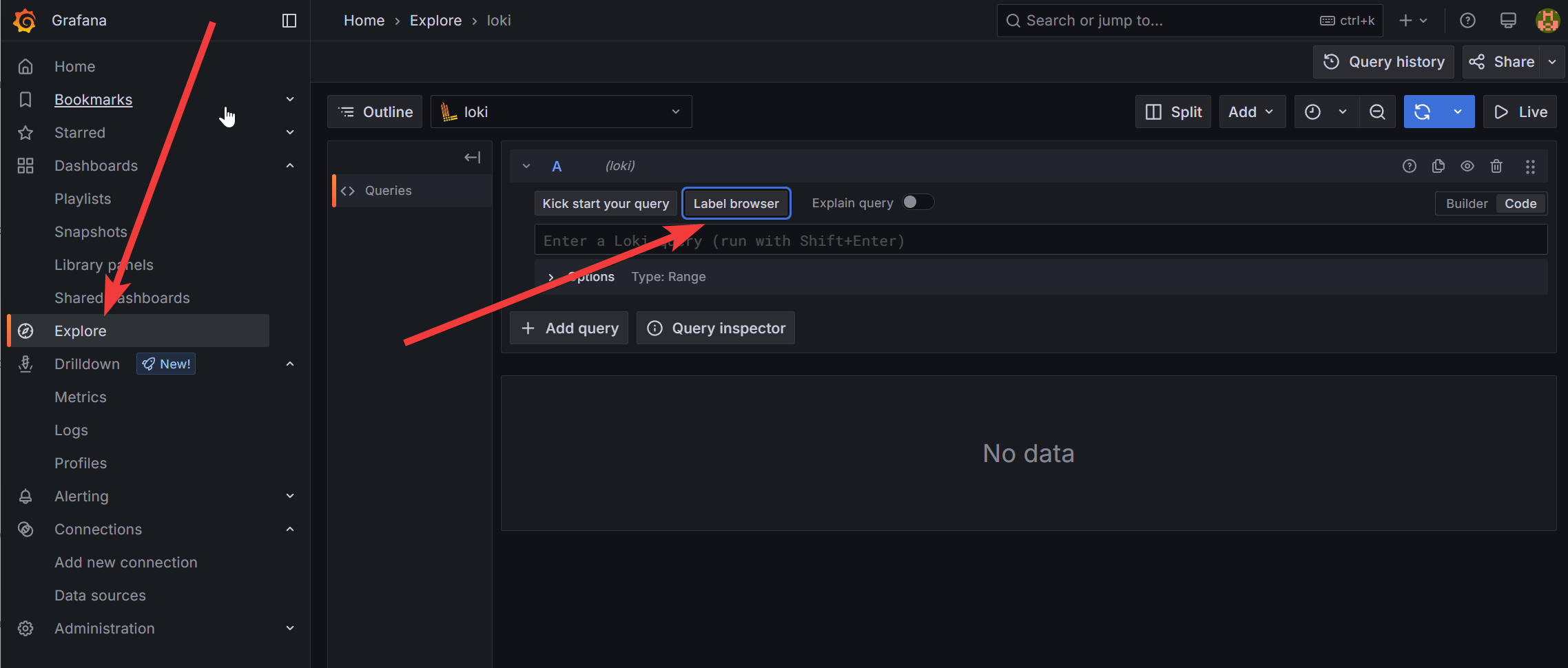
Nach dem Klick auf den „Label Browser„-Button erscheint eine Ansicht, die alle Labels zeigt, die Loki zum jeweiligen Zeitpunkt zur Verfügung stellt. Diese können ausgewählt werden, wobei auch die Wahl mehrerer Labels möglich ist. Danach werden im unteren Bereich die vorhandenen Werte der Labels angezeigt. Diese können wiederum angeklickt werden, wodurch sich letztlich die Query erzeugen lässt. Der folgende Screenshot soll dies verdeutlichen:
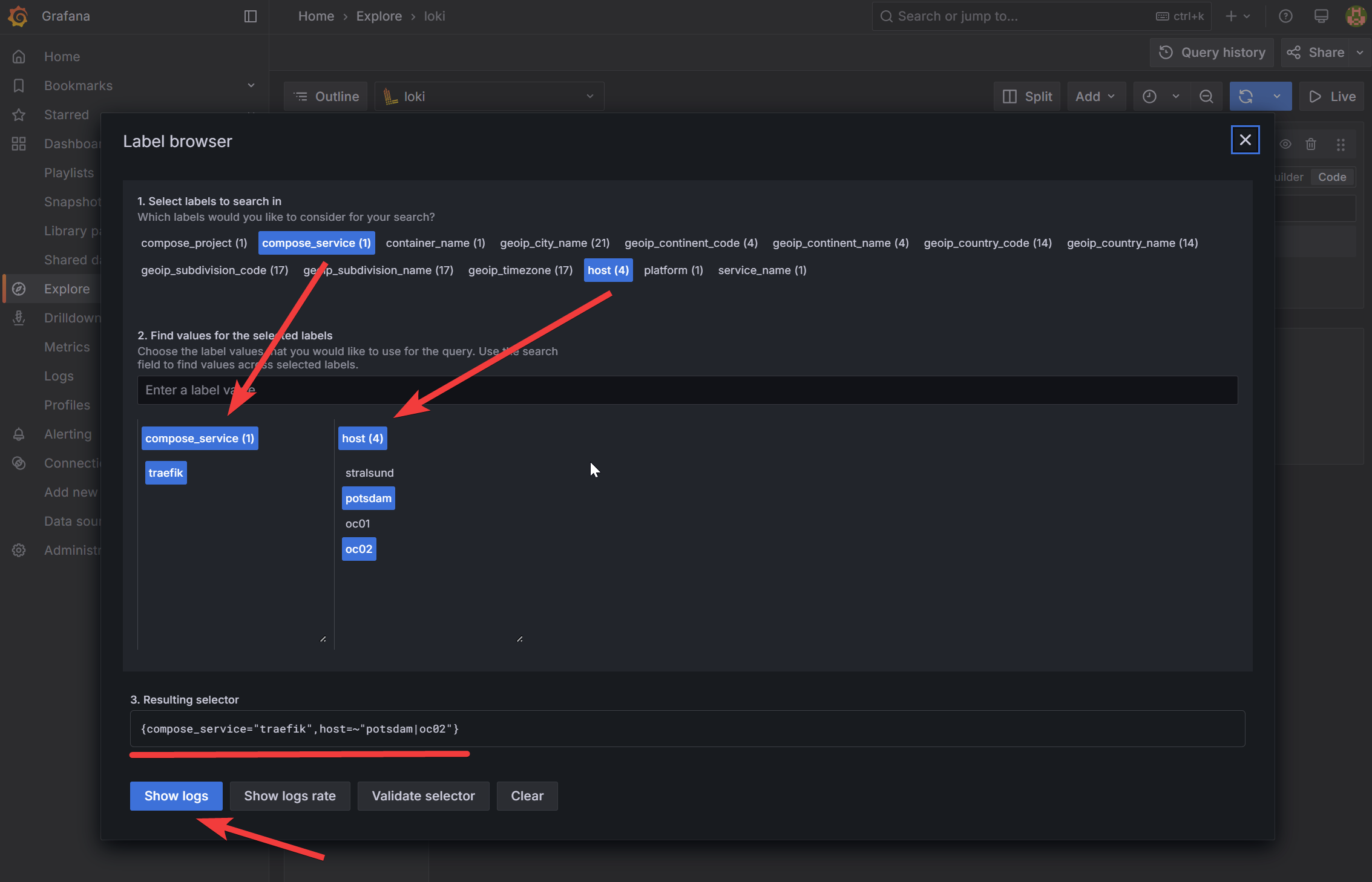
Hier wurde aus dem Label „compose_service“ der Wert „traefik“ ausgewählt. Zunächst erscheint dabei eine Liste von Werten, durch Auswahl ist nur noch der einzelne Wert sichtbar, der durch einen erneuten Klick wieder zurückgesetzt werden kann. Eigentlich ganz einfach, nur wie üblich möchte man eigentlich keine Mausklicks schriftlich erläutern, insofern am besten einfach ausprobieren.
Als weiteres Label „host„, von denen „potsdam“ und „oc02“ gewählt wurden. Daraus entsteht der unten angezeigte Selector. Mittels „Show logs“ wird dieser übernommen, so dass anschließend eine Filterung erfolgt und nur noch die entsprechenden Log-Zeilen angezeigt werden.
Das soll an dieser Stelle zum Thema Grafana genügen, ich werde somit nicht den Aufbau eines Dashboards zeigen, bzw. genaugenommen bin ich noch mitten in der Erstellung eines solchen. In der Grafana Dashboard Übersicht finden sich zwar eine Menge fertiger und vermeintlich einsetzbarer Dashboards, aber bis auf ganz, ganz simple habe ich keines gefunden, das auf Anhieb funktionieren wollte.
Bonus: GeoIP-Einbindung
Die hier genannte Alloy-Konfiguration bindet GeoIP-Dateien ein, insofern möchte ich nun noch ein paar Hinweise geben, wie diese zu erhalten sind. Dafür zeigt sich der Platzhirsch Maxmind zuständig, der neben vielen Diensten und kommerziellen Leistungen rund um GeoIP-Lokalisierung die „GeoLite„-Datenbanken kostenlos in unterschiedlichen Formaten zur Verfügung stellt. Um diese zu erhalten, ist zunächst eine Registrierung bei Maxmind notwendig. Danach können unter „Account“ -> „Manage License Keys“ Lizenzschlüssel für die GeoLite-Datenbanken angelegt werden. Dieser Lizenz-Key sowie die Account-ID sind für den Download der Dateien notwendig. Die GeoIP-Dokumentation beschreibt diesen Prozess sehr gut und ausführlich.
Da sich die GeoIP-Daten jedoch von Zeit zu Zeit ändern bzw. von Maxmind aktualisiert werden, empfiehlt sich ein automatisierter Download. Dabei besitzen die kostenlosen Varianten jedoch eine Beschränkung in der Anzahl Downloads pro Tag, aktuell sind davon maximal 30 erlaubt. Um auf Nummer sicher zu gehen, nutze ich einen Cronjob, der einmal täglich auf einem Server läuft, um die GeoLite-Datenbanken herunterzuladen.
Die einfachste Variante, die Datenbank-Dateien herunterzuladen, ist die Nutzung des von Maxmind zur Verfügung gestellten Clients „geoipupdate„. Da ich diesen nicht direkt per Ubuntu-Paket installieren wollte, wird auch für den Update-Prozess Docker benutzt. Nach dem Motto, wenn schon Docker, dann spricht auch hierbei nichts dagegen, bzw. letztlich steckt der Ansatz dahinter, möglichst wenig direkt ins System installieren zu müssen, was nicht Bestandteil der verwendeten Linux-Distribution ist, um den Aufwand bei System-Upgrades zu verringern.
Mit ein wenig Bash-Bastelei, die letztlich nur dafür zuständig ist, etwaige Fehler beim Update-Prozess zu erkennen und in ein Logfile zu schreiben, ist schließlich das folgende Update-Skript entstanden:
#!/bin/bash
LOGFILE="/home/<MEIN_USERNAME>/services/geoipupdate/cron.log"
WORKDIR="/home/<MEIN_USERNAME>/services/geoipupdate"
ENVFILE="$WORKDIR/.env"
DATADIR="$WORKDIR/geoip"
# Change to working directory
cd "$WORKDIR" || { echo "$(date '+%Y-%m-%d %H:%M:%S') - ERROR: Cannot change to working directory $WORKDIR" >> "$LOGFILE"; exit 1; }
# Rotate logfile if bigger than 100 KB
if [ -f "$LOGFILE" ] && [ "$(stat -c%s "$LOGFILE")" -gt 102400 ]; then
mv "$LOGFILE" "$LOGFILE.old"
fi
# Check Internet connectivity
if ! ping -c1 -W1 1.1.1.1 >/dev/null 2>&1; then
echo "$(date '+%Y-%m-%d %H:%M:%S') - WARNING: No internet connection. Update aborted." >> "$LOGFILE"
exit 1
fi
# Run the Docker container
docker run --rm \
-u "$(id -u <MEIN_USERNAME>):$(id -g <MEIN_USERNAME>)" \
--env-file "$ENVFILE" \
-v "$DATADIR:/usr/share/GeoIP" \
ghcr.io/maxmind/geoipupdate:v7.1
# Check if Docker run was successful
if [ $? -eq 0 ]; then
echo "$(date '+%Y-%m-%d %H:%M:%S') - SUCCESS: GeoIP Update completed successfully." >> "$LOGFILE"
else
echo "$(date '+%Y-%m-%d %H:%M:%S') - ERROR: GeoIP Update failed." >> "$LOGFILE"
exit 1
fi
Um ein direktes Copy-und-Paste zu verhindern, sind hier mein echter Username auf dem System durch „<MEIN_USERNAME>“ ersetzt worden. Die Arbeit wird letztlich durch den Aufruf des Docker-Kommandos erledigt, dabei wird wiederum eine .env-Datei eingebunden, die aus den folgenden Zeilen besteht:
GEOIPUPDATE_ACCOUNT_ID=<die_Maxmind_Account_ID> GEOIPUPDATE_LICENSE_KEY=<der_zuvor_erzeugte_Lizenz_Key> GEOIPUPDATE_EDITION_IDS=GeoLite2-ASN GeoLite2-City GeoLite2-Country
Das Skript wird dann einmal pro Tag per Cronjob aufgerufen, im Logfile finden sich danach die entsprechenden Erfolgs- oder auch Fehlermeldungen.
Die heruntergeladenen Dateien müssen dann nur noch in das Verzeichnis kopiert werden, in dem Alloy die GeoIP-Datenbanken erwartet. Das wäre hier im Beispiel das Stamm-Verzeichnis von Alloy, in dem sich dessen Docker-Compose-File befindet. Es heißt einfach „geoip„, das Mounten in den Alloy-Container sorgt schließlich dafür, dass Alloy darauf zugreifen kann. Für diese Kopie sowie die Verteilung auf die weiteren Server nutze ich jeweils den lsync-Dienst, da dieser bereits auf der Maschine installiert war und somit eine der einfachsten Varianten darstellte.
Nun besteht die Annahme, dass Alloy die GeoIP-Dateien nicht bei jeder Log-Zeile neu öffnet, liest und wieder schließt – dieser Vorgang wäre zumindest sehr aufwändig und würde die Performance ruinieren, sondern einmal beim Start einliest und daraufhin im Speicher hält. Zugegebenermaßen habe ich dies nicht weiter geprüft, und in der stage.geoip-Dokumentation leider nichts zu dem Thema gefunden. Im Gegensatz dazu dürfte bei einem „Reload“ genau das erfolgen – Alloy wird neu gestartet, ergo sollten auch die Konfigurationen neu geladen werden, und damit die GeoIP-Dateien neu eingelesen.
Netterweise besitzt Alloy für den Reload-Vorgang einen HTTP-Endpoint. Da dieser nur auf „localhost“ verfügbar ist (siehe Docker-Compose-File), kann für den Reload der entsprechende Pfad genutzt werden. Der Einfachheit halber läuft auch dies per Cronjob einmal pro Tag, der entsprechende Aufruf lautet „http://localhost:12345/-/reload“ und wird per curl ausgeführt.
Fazit und ein wenig Gemecker am Rande
Damit wäre die Installation zunächst abgeschlossen. Da sich Alloy als umfassende Lösung für Logs, Metriken etc. versteht, wollte ich noch einen Schritt weiter gehen und Alloy für sie Sammlung und Weitergabe von Server-Metriken einsetzen. Dazu hatte ich bis dato das Programm Node Exporter genutzt, dessen Endpoint von Prometheus abgefragt wird. Laut Dokumentation integriert Alloy sogar genau diesen Node Exporter und stellt die Metriken schließlich Prometheus zu.
Nur ergab sich dabei eine kleine Diskrepanz. Im Klartext: Die Dokumentation von Alloy zur Nutzung für das Monitoring von Linux-Servern zeigt am Ende der Pipeline, dass die gesammelten Daten an einen Prometheus-Endpoint zugestellt werden – analog zu Loki, der einen solchen definiert. Der Standard-Weg, wie Prometheus an seine Daten gelangt, ist jedoch genau anders herum – Prometheus fragt in regelmäßigen Abständen die Metriken ab, anstatt sie geliefert zu bekommen.
Zusammengefasst: Prometheus führt einen „Pull“ aus, Alloy möchte hingegen einen „Push“ ausführen. Technisch und theoretisch soll die Bereitstellung eines Prometheus-Endpoints für Metriken zwar funktionieren, aber in der Dokumentation von Prometheus wird – zumindest meinem Verständnis nach – ausdrücklich gewarnt, und zwar beim Thema „Remote Write Receiver“ („It is not suitable for replacing the ingestion via scraping and turning Prometheus into a push-based metrics collection system.„). Daneben besitzt Prometheus noch einen speziellen Push Gateway als zusätzliches Tool, aber auch dies ist anscheinend eine eher ungewöhnliche Konfiguration.
Insofern ergeben sich bereits aus der Dokumentation von Alloy und Prometheus zumindest zwei Ansätze, die sich meines Erachtens widersprechen. Trotz dieses Widerspruchs wollte ich es dennoch versuchen, Prometheus war schnell in einer neuen Installation aufgesetzt, der Endpoint wie angegeben eingerichtet. Dennoch ist es mir nicht gelungen, Alloy zum Push von Metriken an Prometheus zu überreden. Prometheus antwortete mit einem 404-Fehler, also Seite nicht gefunden, Anfrage nicht verstanden oder wie auch immer. Der Endpoint war eingerichtet, aber auch nach mehreren Versuchen und einigem Hin und Her mit ChatGPT, das zwischendurch drölf Mal seine Meinung änderte, war es nicht möglich, die Konfiguration zum Laufen zu bringen.
Letztendlich führte dies alles zu keinem adäquaten Ergebnis, zumindest nicht in endlicher Zeit, weshalb ich wieder zurück auf die Node-Exporter-Lösung gegangen bin, der schön brav in seinem eigenen Container läuft und wie gewohnt von Prometheus erfolgreich abgefragt werden kann. Die funktioniert zwar wunderbar, dennoch bleibt ein suboptimaler Nachgeschmack bei Alloy bzw. dessen Dokumentation. Diese ist ansonsten durchaus ausführlich, wenngleich aufgrund der schieren Menge der Optionen etwas unübersichtlich, aber das Senden an einen Prometheus-Endpoint erwies sich zumindest für mich als Sackgasse.
Alles Weitere kommt irgendwann. Später. Oder noch später. Immerhin kommen die Logs erfolgreich an, Grafana stellt sie wie erwartet dar. Und das Dashboard ist nur eine Frage der Zeit. Ach ja, nur am Rande – ChatGPT hat übrigens meine Empfindung der genannten Diskrepanz bestätigt…



