
Mit Benchmarks ist es ja so eine Sache – analog zu Statistiken, nach dem altbekannten Motto – „Traue keiner Statistik, die du nicht selbst gefälscht hast“. Für einen ersten Eindruck ist der Benchmark des letzten Artikels, der FerretDB mit MongoDB verglichen hat, sicherlich gut und sinnvoll, allerdings hat er meiner Ansicht nach einen entscheidenden Haken: Die Struktur, oder vielmehr die fehlende Struktur der Dokumente.
Schließlich handelt es sich bei MongoDB und FerretDB um Dokumentendatenbanken, der ursprüngliche Benchmark speichert jedoch neben einer Zufallszahl und dem genutzten Thread im Modus für „lange“ Dokumente nur eine 2048 Bytes lange Zeichenkette, die ebenfalls zufällig generiert ist. Ohne die Option „-largeDocs“ fehlt diese sogar, so dass die gespeicherten Datensätze jeweils sehr klein sind.
Neue Dokumente
Um ein wenig mehr Realitätsnähe zu erhalten, habe ich den Benchmark ein wenig erweitert. Über die Struktur kann man sich natürlich trefflich streiten, aber gehen wir mal für dieses Beispiel von einer Datenbank für ein Blog aus. Sicherlich würden dabei Felder wie Autorenname, Titel, Kategorie, ein oder mehrere Tags und natürlich ein längerer Inhalt zum Einsatz kommen. Vielleicht noch ein paar Angaben wie Anzahl von Views, Likes, Kommentaren, oder wie oft der Artikel weitergegeben („geteilt“) wurde.
Ein Artikel könnte auch noch Co-Autoren haben, genau wie eine Zusammenfassung. Und die einzelnen Inhalte der Artikel wären sicherlich etwas länger, würden insofern mehr und auch keine feste Anzahl von Bytes umfassen. Der Fantasie sind hier wie immer keine Grenzen gesetzt, so könnte ein Shop-System etwa eine ähnliche Struktur besitzen, anstatt Blog-Inhalt wäre ein längeres Feld für Artikel-Details vorgesehen, anstatt Likes vielleicht Anzahl der Empfehlungen usw.. In einer relationalen Datenbank würde die Modellierung naturgemäß anders aussehen, aber einerseits sollen hier Dokumentendatenbanken zum Einsatz kommen, und andererseits, sowohl der Einfachheit halber – und erst recht, um in einem Benchmark nutzbar zu sein, sollen alle „Blog-Artikel“ in einer Collection platziert werden.
Die erweiterte Version bietet somit einen neuen Typ „insertDoc„, mit dem jeweils Dokumente mit einer gewissen Struktur eingefügt werden. Diese sieht wie folgt aus:
| Feld: | Typ und Inhalt |
| threadRunCount | Integer; Angabe, von welchem Thread der Datensatz eingefügt wurde |
| rnd | Integer, Zufallszahl |
| v | 1; übernommen aus ursprünglichem Quellcode |
| title | String, 30 Zeichen, aus Blindtext („Lorem ipsum“) generiert |
| author | String, zufällig gewählter Autorenname (aus Autoren-Array) |
| guest | String, zufällig gewählt aus 10.000 Möglichkeiten „guest_0000“ – „guest_9999“ – im späteren Verlauf hinzugefügt |
| co_authors | Array aus Strings, 1 – 3 Co-Autoren, zufällig gewählt aus Autoren-Array |
| summary | String, 100 Zeichen, aus Blindtext |
| content | String, 2000 – 5000 Zeichen, aus Blindtext, eingefügt werden Stichwörter (aus Tags-Array) mit einer Wahrscheinlichkeit von 10% während der Generierung |
| tags | Array aus Strings, 4 – 6 Tags, zufällig gewählt aus Tags-Array |
| category | String, zufällig gewählt aus Kategorien-Array |
| timestamp | Timestamp, zufällig gewählt aus dem Zeitraum der letzten 2 Jahre |
| views | Integer, Zufallszahl 0 – 10000 |
| comments | Integer, Zufallszahl 0 – 500 |
| likes | Integer, Zufallszahl 0 – 1000 |
| shares | Integer, Zufallszahl 0 – 200 |
Obligatorisch ist die ObjectId, die von der jeweiligen Datenbank selbst beim Einfügen generiert und somit ebenfalls Bestandteil eines Datensatzes wird. Und natürlich mag man geteilter Ansicht sein, ob diese Struktur nun unbedingt die Realität widerspiegelt oder eher nicht. Meiner Ansicht nach ist eine solche Struktur jedenfalls besser geeignet als eine zufällige Zeichenkette, um Find-Operationen auszuführen.
Neue Find-Operationen
Da wären wir auch bereits beim zweiten Punkt – der bisherige Benchmark hat Insert-, Update-, Delete- und die sog. Upsert-Operationen ausgeführt, aber sich nicht um die Selektion gekümmert. Wobei das nicht ganz richtig ist, denn implizit wurden etwa bei Updates zwar Find-Operationen ausgeführt, diese bezogen sich jedoch nur auf die jeweils eindeutige ObjectId, sozusagen den Primary Key.
Auch hier ging die Überlegung in Richtung Realitätsnähe, denn die häufigste Operation ist mit einiger Sicherheit die Selektion, also das Suchen und Finden bzw. Anzeigen von Datensätzen. Um beim Blog-Beispiel zu bleiben – dass Blog-Artikel weitaus häufiger angezeigt als aktualisiert oder gelöscht werden, sollte einigermaßen selbstverständlich sein, auch in dem Falle, wenn die Views nur von ein paar Bots generiert werden. Die in der Praxis wohl eher selten anzutreffende Speicherung der Anzahl von Likes, Kommentaren etc. lassen wir mal außen vor – ich wollte letztlich einfach noch ein paar weitere Angaben in die Dokumentenstruktur bringen.
Die ebenfalls als weiterer Typ des Parameters „-type“ realisierte Operation „findDoc“ sorgt nun dafür, dass – noch relativ einfache – Find-Operationen ausgeführt werden. Auch hier ist eine Zufallskomponente vorhanden, denn die Auswahl erfolgt aus folgenden Operationen:
| Filter | Inhalt | n | n neu |
| „author“ | String, zufällig gewählter Autor aus Autoren-Array | 1 | 1 |
| „guest“ | String, „guest_0000“ bis „guest_9999“, zufällig – im späteren Verlauf hinzugefügt | 2 | |
| „tags“ | ein Element des Tags-Arrays ($elemMatch) muss übereinstimmen mit einem zufällig ausgewählten Tags ($eq) |
2 | 3 |
| „timestamp“ | Artikel neuer als zufällig ausgewähltes Datum innerhalb des vergangenen Jahres ($gt) |
3 | 4 |
| $text | Volltext-Suche ($search) im Content-Feld, für die Suche genutzt werden die Begriffe aus dem Tags-Array |
4 | 5 |
Bei einer ausreichend großen Anzahl von Operationen bzw. einer längeren Dauer des Benchmark-Laufs wird sich dank der Zufallsauswahl die Anzahl der jeweiligen Find-Operationen aneinander angleichen. Zum besseren Vergleich ist es ebenfalls möglich, die einzelnen Find-Operationen getrennt voneinander auszuführen. Der Parameter „-queryType n“ wählt eine einzelne Find-Operation aus, bzw. falls gar nicht oder auf 0 gesetzt, entscheidet der Zufall.
Auch diese Operationen sind jetzt weder empirisch fundiert oder der Realität entnommen, vielmehr handelt es sich um eine Idee von Selektionen, die typischerweise in einer Anwendung vorkommen könnten – man klickt auf den Autorennamen oder in einer Tag-Liste, und die Suche wird ausgeführt, man möchte sich die Artikel beginnend ab einem Datum anzeigen lassen, oder man ist an einem Begriff interessiert, der in einem oder mehreren Artikeln doch eigentlich vorkommen müsste.
Der Index kommt ins Spiel
Des Weiteren lassen sich nun mittels Parameter „-useIndex“ Indizes bei bzw. vor der Ausführung der insertDoc-Operationen erzeugen. Genau wie die Struktur der Dokumente und die Find-Operationen ist das Setzen der Indizes momentan fest im Code verankert. Zusammengesetzte Indizes (Compound Indexes) oder Unique werden aktuell nicht genutzt.
| Feld | Index |
| „author“ | 1 (aufsteigend) |
| „guest“ | 1 (aufsteigend) – im späteren Verlauf hinzugefügt |
| „tags“ | 1 (aufsteigend) |
| „timestamp“ | -1 (absteigend) |
| „content“ | „text“ (Volltext-Index) |
Und schließlich habe ich eine neue Ablauf-Sequenz mit dem Namen „runDoc“ eingefügt, die zunächst die Dokumente einfügt, d.h. die „insertDoc„-Operation, und anschließend die Find-Operationen, ergo „findDoc„, ausführt. Bei letzteren kommen alle hier genannten Queries in zufälliger Reihenfolge zum Einsatz. Da jedoch die Volltextsuche in einem Feld nur möglich ist, wenn zuvor darauf ein Volltext-Index gesetzt wurde, entscheidet der Parameter „-useIndex“ darüber, ob die Volltextsuche bei der Zufallsauswahl mit genutzt wird. Ansonsten werden nur die ersten drei Queries verwendet. Umgekehrt würde eine Volltextsuche auf einem nicht indizierten Textfeld zu einer Fehlermeldung inklusive Abbruch der Suche führen.
Die Voraussetzungen für die Benchmarks sind dieselben wie im letzten Artikel genannt: Eine kleine VM für die Datenbank (2 CPUs, 8 GB RAM, 500 GB Plattenplatz), MongoDB und FerretDB als Docker-Container, zum Einsatz kamen MongoDB 8.0.5 als von der Community gepflegtes Docker-Image, FerretDB in der Version 2.0 GA, dessen Docker-Image von FerretDB Inc. zur Verfügung gestellt wird. Der Benchmark selbst wurde ausgeführt auf einer VM mit ähnlichen Daten, alle Benchmarks wurden per Shell-Skript aufeinander folgend gestartet.
Benchmark Teil 1
Die Eckdaten der einzelnen Durchläufe:
- Getestet wurden jeweils MongoDB und FerretDB.
- Zunächst 10 Threads, später mit 30 Threads wiederholt.
- Operationen:
insertDocwie oben beschrieben, dannfindDocmit allen genannten „-queryType„-Filtern; Limit 10, keine Sortierung - 300.000 Dokumente eingefügt, jeweils 100.000 Dokumente gesucht bzw. gefunden (
findDoc) - Ausführung zunächst ohne Index, anschließend Wiederholung mit Index
Die Ergebnisse im Einzelnen – zunächst alle Operationen mit 10 Threads ohne das Setzen der Indizes:
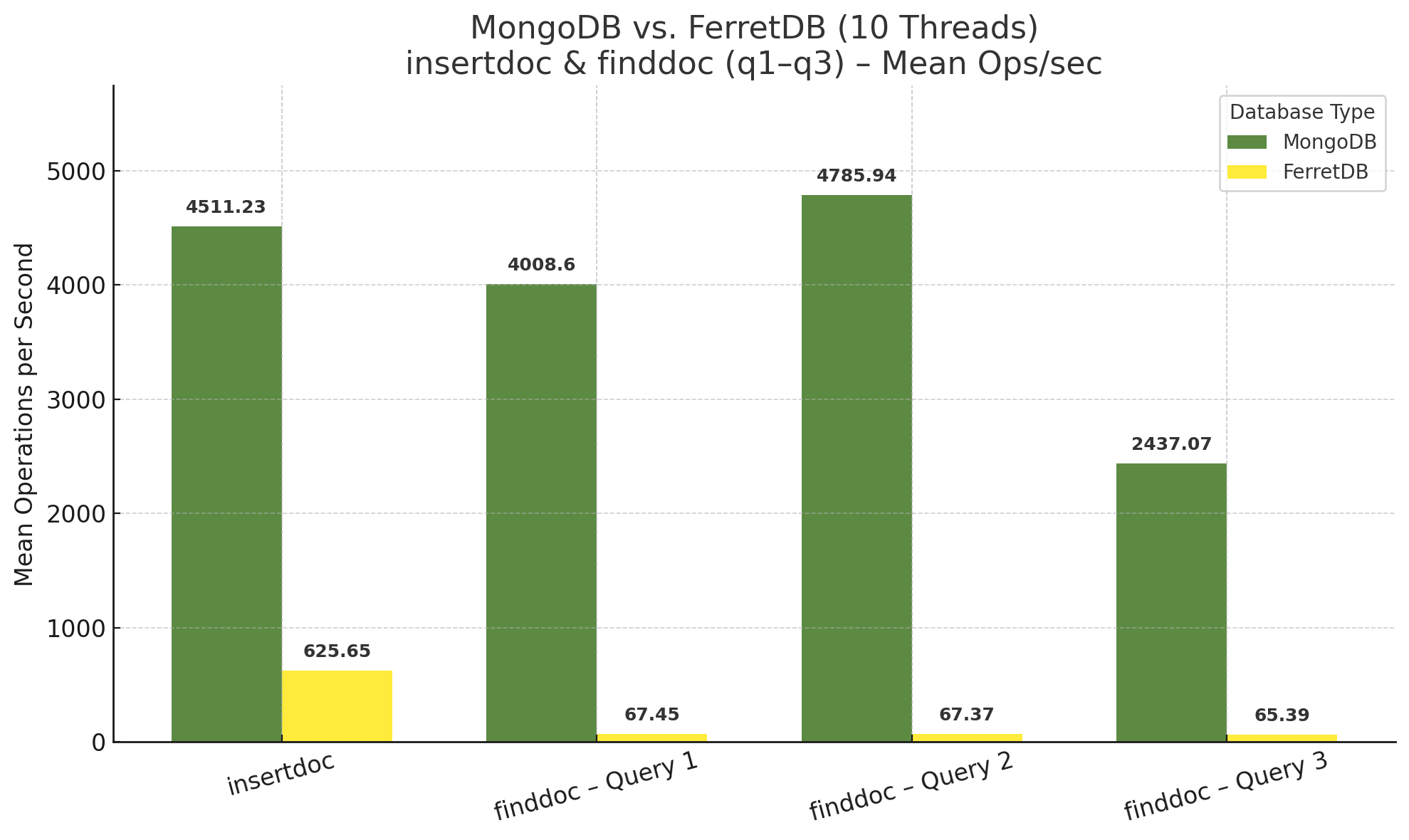
Die hier angegebenen Query-Nummern stimmen mit dem Parameter „-queryType“ n überein, wie in der Tabelle oben genannt. Die Volltextsuche (zunächst in Query 4) fehlt hier, da sie wie erwähnt ohne Index nicht ausgeführt werden konnte.
Bei den Insert-Operationen ist eine hohe Ähnlichkeit zu den Ergebnissen des letzten Benchmarks zu finden. Die Anzahl der Operationen pro Sekunde bewegt sich in derselben Kategorie, sowohl bei MongoDB als auch bei FerretDB. Eine Vergleichbarkeit zu den bisherigen Benchmarks ist für die Find-Queries hingegen nicht gegeben. MongoDB ist hier schlicht und einfach um Größenordnungen schneller, und FerretDB hat eine Menge aufzuholen.
Ein wenig spannender wird das nächste Diagramm – erneut alle Operationen bei 10 Threads, jedoch mit vorherigem Setzen der Indizes wie oben beschrieben:
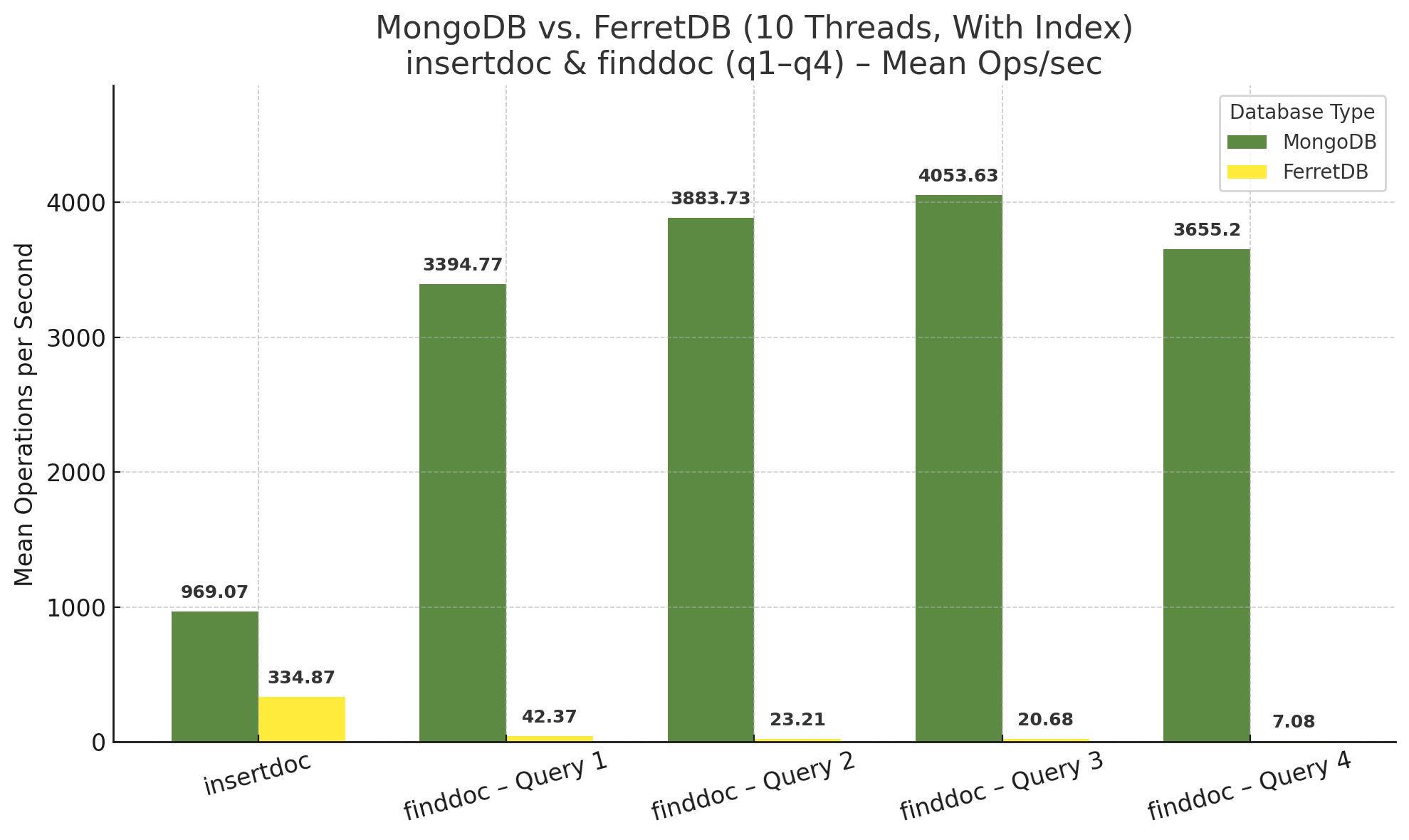
Während FerretDB beim Insert etwa noch die halbe Leistung zeigt, die Anzahl der Operationen sich somit knapp halbiert hat, ist bei MongoDB ein deutlicher Einbruch festzustellen – hier beträgt die Anzahl der Insert-Operationen pro Sekunde weniger als ein Viertel im Vergleich zur Ausführung ohne Index. Auf den ersten Blick seltsam, beim zweiten auch nicht besser, dazu gleich mehr.
Aber auch die Find-Operationen zeigen für MongoDB kein eindeutiges Bild. Während die ersten beiden Queries tatsächlich ein wenig langsamer geworden sind, wurden bei der dritten, der Suche anhand von Zeitangaben, wesentlich mehr Operationen pro Sekunde erreicht. Auch die Volltextsuche ist bei MongoDB als durchaus schnell zu bewerten.
Bei FerretDB hingegen… irgendwie weiß ich gar nicht, was man dazu schreiben soll. Dass die Volltextsuche nur mit entsprechendem Index funktioniert, ist die eine Sache, die Anzahl der Operationen pro Sekunde sind nochmal eine ganz andere. Alle anderen Queries sind ebenfalls langsamer geworden, und zwar im Bereich von einem bis zwei Drittel. Hier könnte man sich durchaus fragen, ob – zum aktuellen Zeitpunkt – das Anlegen von Indizes überhaupt sinnvoll ist, falls man keine Volltextsuche benötigt. Ich habe es tatsächlich mehrfach geprüft, die Indizes wurden tatsächlich gesetzt, db.testdata.getIndexes() lieferte zumindest die entsprechenden Angaben zurück.
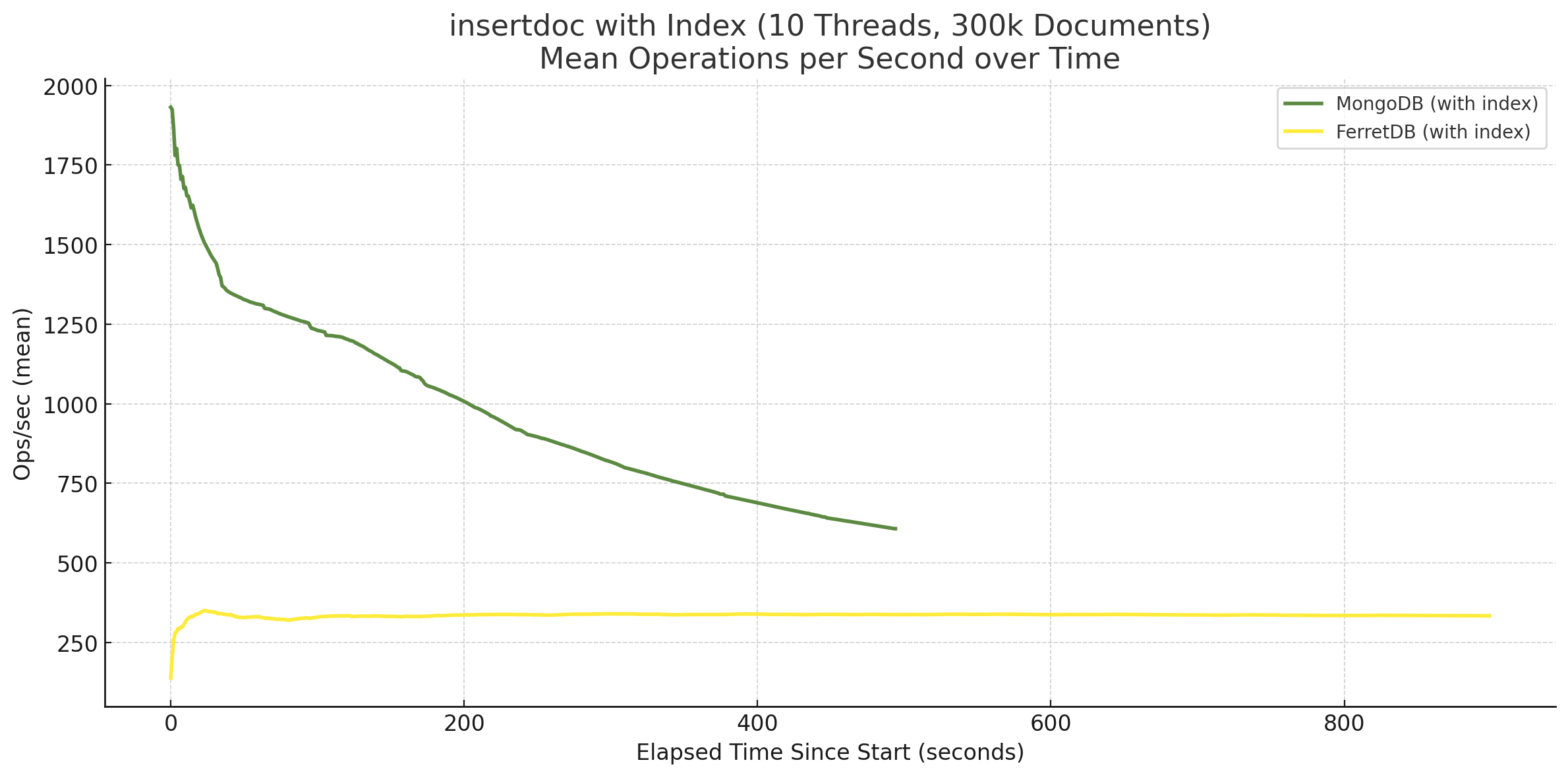
Die im Durchschnitt wesentlich geringere Anzahl an Insert-Operationen pro Sekunde bei MongoDB mit Index wollte ich mir noch ein wenig genauer ansehen. Denn während des Benchmark-Laufs ist bereits aufgefallen, dass die Anzahl an Operationen pro Sekunde immer mehr abgenommen haben, je länger der Benchmark lief bzw. je mehr Dokumente eingefügt wurden. Zum Vergleich die Darstellung im Zeitverlauf:
Ohne Index sieht das Diagramm hingegen wie folgt aus:
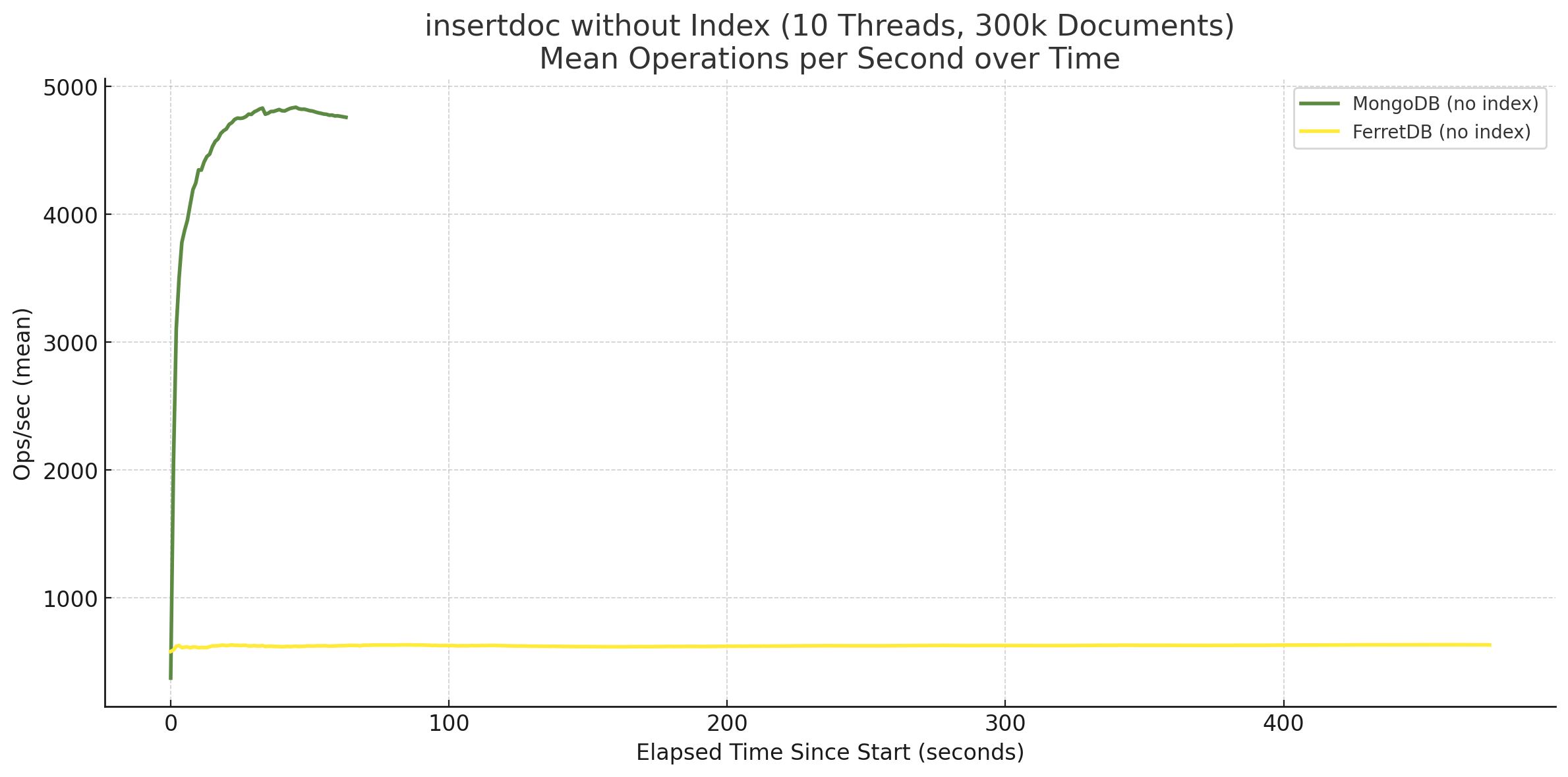
FerretDB bleibt in beiden Fällen, ob ohne oder mit Indizes, auf konstantem Niveau. Einem zugegebenermaßen niedrigen Niveau, aber die Performance ändert sich im weiteren Verlauf nicht. MongoDB hingegen pendelt sich ohne Indizes auf einem hohen Niveau ein, wie auch bereits im letzten Benchmarks beim Einfügen von 1 Mio. Dokumente festgestellt. Mit Index nimmt die Anzahl an Insert-Operationen pro Sekunde jedoch immer mehr ab. Das ging so weit, dass bei einer höheren Anzahl von Dokumenten MongoDB die Leistung von FerretDB unterschritten hat.
Tatsächlich hatte ich zunächst versucht, die Benchmarks erneut mit 1 Mio. Dokumente auszuführen, jedoch näherte sich MongoDB immer mehr der Null-Linie, weshalb mir die Anzahl von 300.000 Dokumente als ein praktikabler Kompromiss erschien. Natürlich kann man argumentieren, dass die verwendete Hardware für den gesamten Benchmark eine zu geringe Leistung aufweisen würde, und das wäre auch insgesamt nicht von der Hand zu weisen.
Dagegen spricht jedoch, dass die Kurve der Insert-Operationen von Anfang an nach unten zeigt, also nicht etwa zunächst eine gewisse Anzahl von Dokumenten mit hoher Geschwindigkeit einfügt und dann – bei Erreichen der Leistungsgrenzen – rapide abfällt. Zu Beginn sinkt die Leistung sogar schneller als nach einem gewissen Punkt bzw. einer gewissen Anzahl von eingefügten Dokumenten. In der Praxis, also bei einer realen Anwendung würde ich an dieser Stelle tiefer einsteigen, etwa zunächst prüfen, welcher der vier gesetzten Indizes zu dieser Verlangsamung führt, oder ob alle betroffen sind. Dennoch können die Ergebnisse hier erstmal so stehen gelassen werden – inklusive der entsprechenden Merkwürdigkeit.
Nach den Benchmarks mit 10 parallelen Threads folgten alle Durchläufe nochmal mit 30 Threads. Zunächst die Ergebnisse ohne Index:
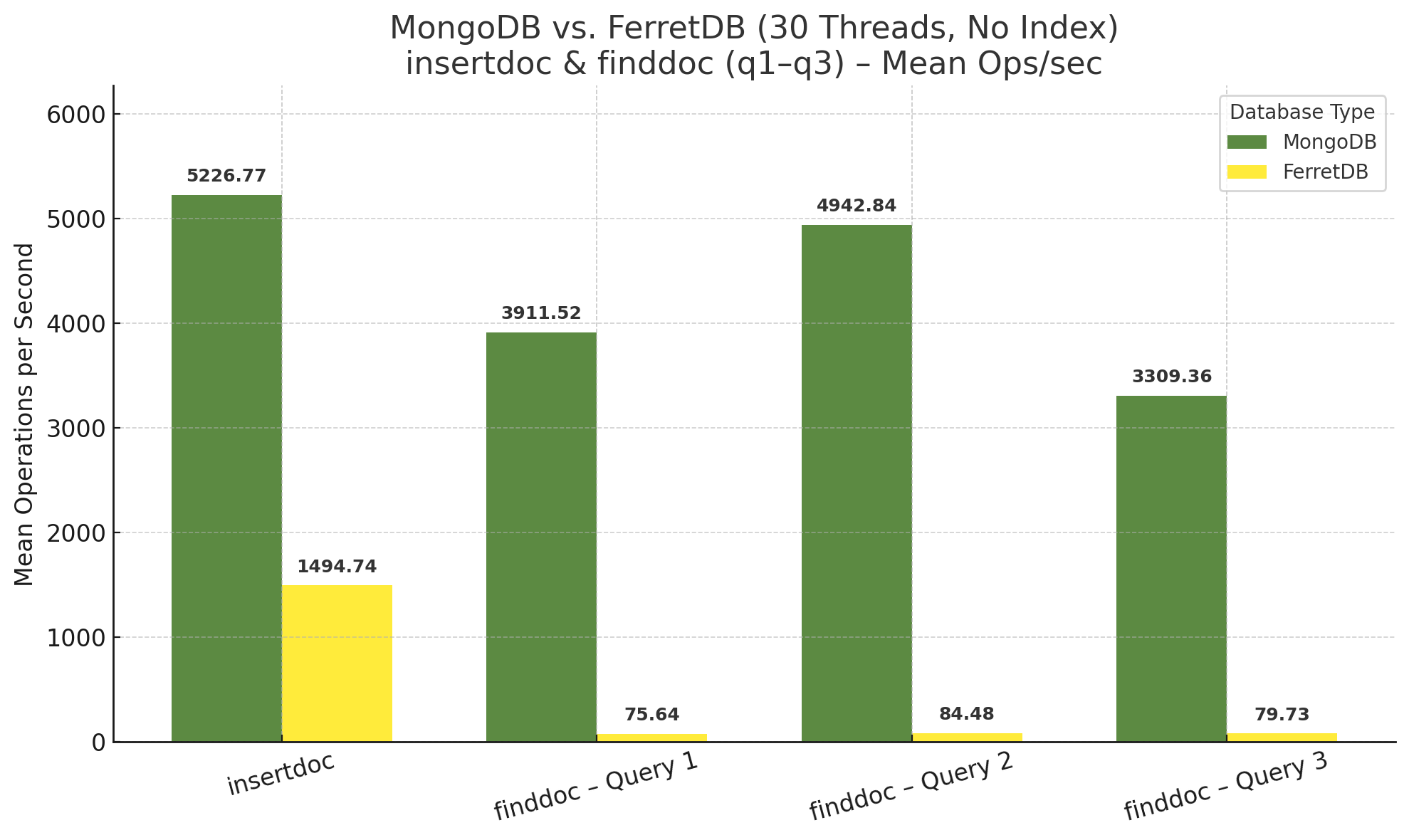
Erneut ist zu beobachten, dass FerretDB von der höheren Anzahl Threads bei den Insert-Operationen profitieren kann. Die Anzahl der Operationen pro Sekunde ändert sich bei MongoDB nur ein wenig, ist sogar gestiegen im Vergleich zu 10 Threads. Bei den Find-Operationen sehen die Ergebnisse ebenfalls sehr ähnlich aus, bei MongoDB sogar fast identisch, auch bei FerretDB gibt es nur geringe Zuwächse.
Mit Index zeigt sich ein ähnliches Bild:
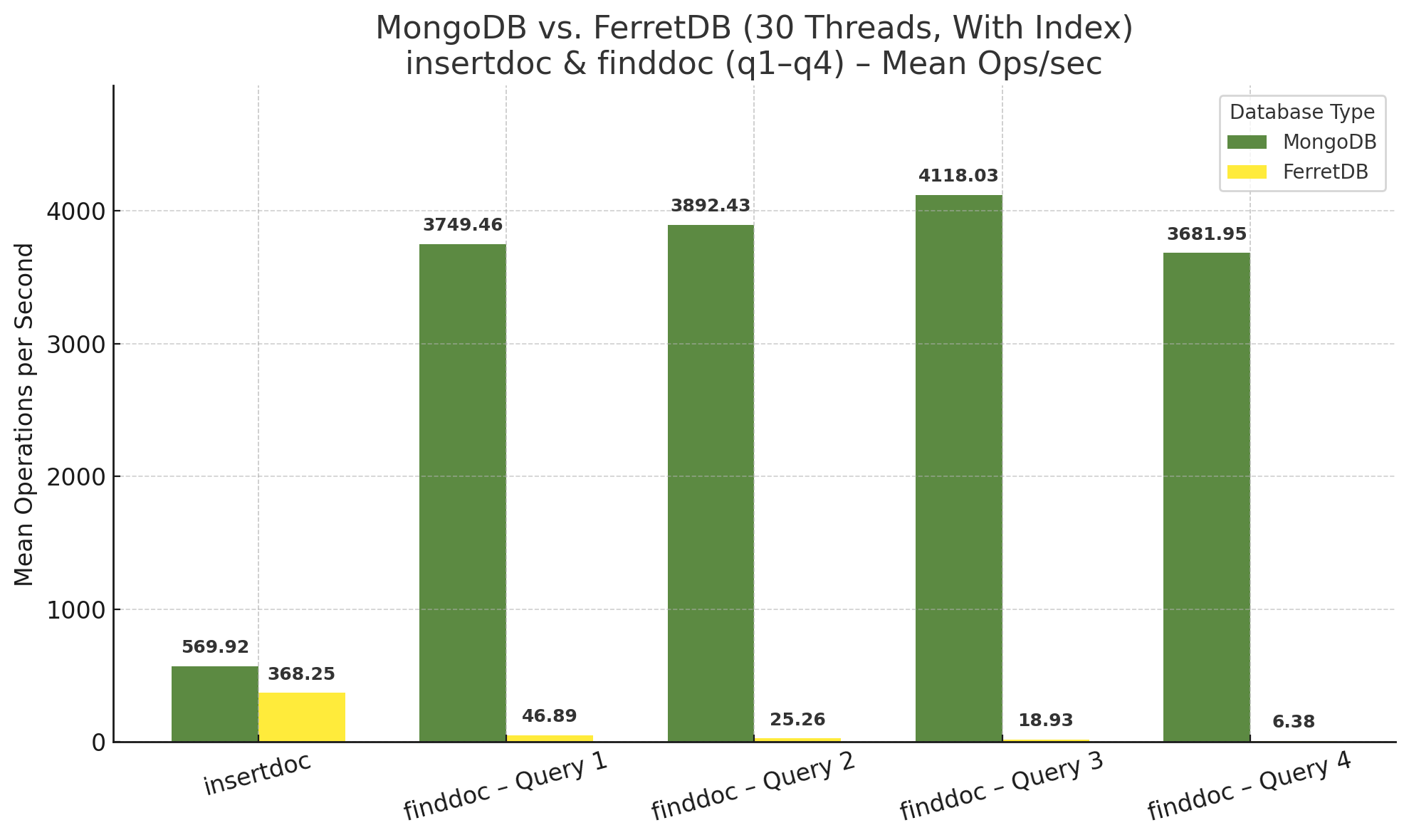
Die schlechten Ergebnisse von MongoDB beim Insert erklärt wiederum das Diagramm des Zeitverlaufs:
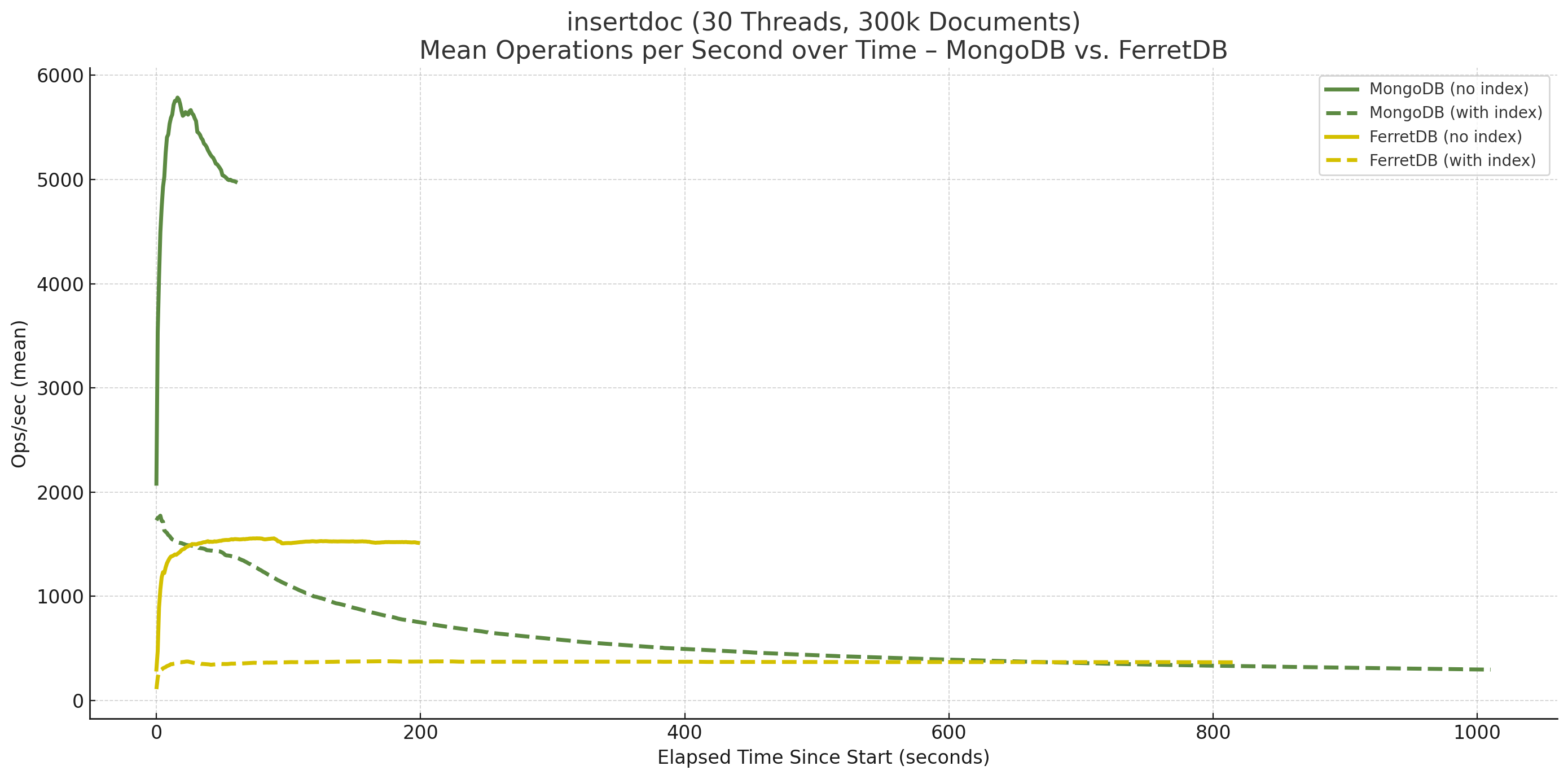
MongoDB unterschreitet ab einem gewissen Punkt bei 30 Threads sogar noch die Anzahl der Insert-Operationen pro Sekunde von FerretDB.
Index – nein, doch, oh!?
So weit, so gut. Oder eher schlecht. Insbesondere die nicht nur langsam, sondern auch seltsam erscheinende Performance von FerretDB hat mir keine Ruhe gelassen. Die anfänglichen Fragen, ob die Indizes einerseits genutzt werden, und andererseits so in der Form überhaupt sinnvoll sind, endeten in einer kleinen Odyssee, die von einer Prüfung der Indizes auf der MongoDB-Shell-Ebene mittels getIndexes() bis hin zu RUM-Indizes von PostgreSQL führen.
Um es vorweg zu nehmen – die Indizes wurden korrekt gesetzt, nur entsprachen die Ergebnisse nicht wirklich den Erwartungen bei der Verwendung eines Index. Das vermeintliche Allheilmittel der SQL-Datenbanken verlangte hier etwas mehr Aufmerksamkeit, weshalb der nächste Schritt darin bestand, den Benchmark erneut ein wenig zu erweitern. Und um schon wieder ein wenig (auf gut neudeutsch) zu spoilern – es hat sich gelohnt!
Der erste Schritt bestand darin, die Ausgabe von explain() zu prüfen, bei FerretDB bzw. MongoDB in der Shell z.B. mittels:
db.testdata.find({ author: "Alice Example" }).explain("executionStats")
Das führte immerhin zu einer etwas länglichen Ausgabe von:
{
queryPlanner: {
Plan: {
'Plan Rows': 150083,
'Plan Width': 915,
'Recheck Cond': "(document OPERATOR(documentdb_api_catalog.@=) 'BSONHEX1f00000002617574686f72000e000000416c696365204578616d706c650000'::documentdb_core.bson)",
Alias: 'collection',
'Total Cost': 9228.81,
Plans: [
{
'Node Type': 'Bitmap Index Scan',
'Parent Relationship': 'Outer',
'Async Capable': false,
'Total Cost': 0,
'Plan Rows': 3002,
'Parallel Aware': false,
'Index Name': 'author_1',
'Startup Cost': 0,
'Plan Width': 0,
'Index Cond': "(document OPERATOR(documentdb_api_catalog.@=) 'BSONHEX1f00000002617574686f72000e000000416c696365204578616d706c650000'::documentdb_core.bson)"
}
],
'Node Type': 'Bitmap Heap Scan',
'Parallel Aware': false,
'Async Capable': false,
'Relation Name': 'documents_412',
'Startup Cost': 37.52
}
},
explainVersion: '1',
command: {
find: 'testdata',
filter: {
author: 'Alice Example'
},
'$db': 'benchmarking'
},
serverInfo: {
host: '0c0017fd6874',
port: 27017,
version: '7.0.77',
gitVersion: '2214721e51d64be04ad016f401d0abf8a335993e',
ferretdb: {
version: 'v2.0.0'
}
},
ok: 1
}
Zusammengefasst – und wenn ich die Angaben richtig verstanden habe – nutzt PostgreSQL hier den Index „author_1„, durchsucht diesen und erstellt eine Bitmap mit potenziellen Treffern („Bitmap Index Scan“), die wiederum als Ausgangspunkt dient, um die Daten aus der Tabelle zu lesen („Bitmap Heap Scan“), wobei die „Recheck Cond“, also eine erneute Überprüfung der Bedingung, angewendet wird. Die BSON-Darstellung entspricht dabei dem übergebenen Filter, im Beispiel der Suche Find-Operation nach dem Namen eines Autors.
Dass überhaupt Indizes in PostgreSQL angelegt wurden, lässt sich natürlich auch auf PostgreSQL-Ebene überprüfen. Im Falle der Installation als Docker-Container lässt sich dazu der Port im Compose-File öffnen:
services:
postgres:
image: ghcr.io/ferretdb/postgres-documentdb:17-0.102.0-ferretdb-2.0.0
platform: linux/amd64
restart: always
ports:
- 5432:5432
[...]
Nach einem Restart kann mit einem entsprechenden PostgreSQL-Client darauf zugegriffen werden, ich nutze dazu ganz gerne das freie Tool „HeidiSQL„, das inzwischen nicht nur für MySQL/MariaDB gute Dienste leistet. Da die DocumentDB-Extension das Kommando über die Datenbank hat, finden sich die Namen von Datenbank (hier: „benchmarking„) oder Collection („testdata„) nicht wieder, vielmehr befinden sich die Collections als Tabellen in der Datenbank namens „documentdb_data“ und tragen Namen wie „documents_n„, wobei n einfach durchnummeriert wird.
Hier lässt sich quasi „roh“ mit DocumentDB über die API kommunizieren, wie auf der GitHub-Seite von DocumentDB beschrieben. Aber es lassen sich ebenfalls reine PostgreSQL-Kommandos ausführen, um etwa Informationen über die vorhandenen Indizes auszulesen. Aus der obigen Explain-Ausgabe ist zu lesen, dass die entscheidende Tabelle („Relation Name“) „documents_412“ heißt, was sich für die entsprechende Query verwenden lässt:
SELECT indexrelid::regclass AS index_name,
pg_get_indexdef(indexrelid) AS definition
FROM pg_index
WHERE indrelid = 'documents_412'::regclass;
Die Ausgabe lautete wie folgt:
index_name; definition
collection_pk_412; CREATE UNIQUE INDEX collection_pk_412 ON documentdb_data.documents_412 USING btree (shard_key_value, object_id)
documents_rum_index_98; CREATE INDEX documents_rum_index_98 ON documentdb_data.documents_412 USING documentdb_rum (document documentdb_api_catalog.bson_rum_single_path_ops (path=author, tl='2699'))
documents_rum_index_99; CREATE INDEX documents_rum_index_99 ON documentdb_data.documents_412 USING documentdb_rum (document documentdb_api_catalog.bson_rum_single_path_ops (path=tags, tl='2699'))
documents_rum_index_100; CREATE INDEX documents_rum_index_100 ON documentdb_data.documents_412 USING documentdb_rum (document documentdb_api_catalog.bson_rum_single_path_ops (path='timestamp', tl='2699'))
documents_rum_index_101; CREATE INDEX documents_rum_index_101 ON documentdb_data.documents_412 USING documentdb_rum (document documentdb_api_catalog.bson_rum_text_path_ops (weights='{ "content" : 1.0 }'))
Hinweis: Ich habe diese Zeilen einfach per HeidiSQL als „Delimited Text“ aus der Ergebnistabelle heraus kopiert.
In der verwendeten Version des Benchmarks wurden also neben dem primären und unique Index für die ObjectID vier weitere Indizes erstellt, was genau den Vorgaben entspricht. Der Name der angelegten Indizes legt den Schluss nahe, dass es sich um eine angepasste Variante des RUM-Index handelt, entsprechende Hinweise dazu finden sich bislang jedoch nur im Quellcode, Microsoft verweist dabei auf die GitHub-Seite der Entwickler sowie auf die Erweiterungsmöglichkeiten der sog. GIN-Indizes. In aller Kürze: Der RUM-Index ist eine PostgreSQL-Extension, die wiederum auf dem GIN-Index basiert und Volltextsuchen mit effizientem Ranking (z.B. nach Relevanz) optimiert. Er ermöglicht schnelle Abfragen mit Sortierung und unterstützt zusätzliche Metriken wie numerische Werte oder Zeitstempel.
Nach dieser kleinen Odyssee, die immerhin zur Erkenntnis führte, dass die Indizes wie gewünscht angelegt und sogar verwendet wurden, stellte sich noch immer die Frage nach der dennoch nicht vorhandenen Geschwindigkeit. Ein paar mehr oder minder spontane Ideen gab es natürlich.
Zum Beispiel der Mehraufwand durch die Recheck-Operation. Falls die Bitmap beim „Bitmap Index Scan“ zu groß wird bzw. der dafür konfigurierte Speicher zu klein ist, wird sie zu einer „verlustbehafteten“ Bitmap umgewandelt. Bei der Suche muss daher die Scan-Bedingung erneut geprüft werden, um zu entscheiden, welche Zeilen zurückgeliefert werden sollen. Mehr Speicher könnte hier helfen, aber wie eingangs erwähnt handelte es sich um die Standard-Konfiguration ohne weitere Optimierungen, sowohl auf Seiten von FerretDB, als auch bei PostgreSQL.
Der Index-Zugriff könnte auch einfach Overhead beim Lesen verursachen, da nicht nur auf die Collection selbst, sondern auch auf den Index zugegriffen werden muss. Insbesondere bei einer eher knapp bemessenen VM mit ebenfalls eher wenig performanten Festplatten-Zugriffen könnte dies zur mangelnden Geschwindigkeitssteigerung beitragen.
Darüber hinaus könnte die Ursache in den gespeicherten Daten selbst liegen. Der bisherige Benchmark speichert im Feld „author“ genau zehn unterschiedliche Namen. Bei einer Anzahl von 300.000 Datensätzen ergibt dies – bei optimaler, zufälliger Verteilung – ca. 30.000 Datensätze mit identischen Inhalten. Insofern reduziert die Verwendung des Index zwar die absolute Datenmenge, aber die Anzahl der Datensätze ist immer noch relativ hoch und folglich verbunden mit entsprechendem I/O- und Recheck-Aufwand.
Zwei Schritte vor, einer zurück: Erweiterungen des Benchmarks
Insbesondere um Letzteres zu prüfen, ist die nächste Erweiterung in die Dokumente des Benchmarks eingeflossen. Ein neues Feld („guest„) wurde hinzugefügt, in dem anstatt wie bei „author“ nicht nur 10 unterschiedliche Namen gespeichert werden, sondern es besitzt nun eine Kardinalität von 10.000. Somit werden wesentlich mehr unterschiedliche Werte bzw. Namen in diesem Feld abgelegt und beim Query ebenfalls zufallsgesteuert abgefragt. Dies ermöglicht eine detailliertere Betrachtung über die Funktionalität des Index, der ebenfalls für dieses Feld angelegt wird.
Natürlich habe ich mich während der Tests auch weiterhin mit der Ausgabe von „.find(...).explain("executionStats")“ beschäftigt, aber im Gegensatz zu MongoDB liefert FerretDB zum aktuellen Stand keine Angaben von „nReturned„, „executionTimeMillis„, „totalDocsExamined„, „totalKeysExamined“ und ähnlichen zurück, sondern bezieht sich nur auf den „queryPlanner“ von PostgreSQL, der für unterschiedliche Abfragen jedoch dieselben Werte nennt.
Eine weitere Ergänzung ist die Option, die Anzahl der zurück gelieferten Dokumente flexibel zu bestimmen. Die bisher genutzte Anzahl von 10 Dokumenten mag zwar realistisch sein, etwa bei der Abfrage von Listen mit 10 Elementen, aber verursacht auch einigen Overhead (Recheck, Speicherzugriffe, Dekodieren). Um diesen Einfluss genauer bestimmen zu können, gibt es nun die Option „-limit„, mit der die Anzahl der Dokumente angegeben wird, die Standard-Einstellung beträgt wie bisher 10.
Zuletzt kann beim Setzen der Indizes mit der zusätzlichen Option „-useIndexFullText“ angegeben werden, ob ein solcher überhaupt angelegt wird. Auch dies hat einigen Einfluss auf die Performance beim Einfügen von Dokumenten. Dieselbe Option bestimmt ebenfalls, ob bei den Find-Operationen bei der Zufallsauswahl die Volltextsuche eingebunden oder eben nicht genutzt wird.
Benchmark Teil 2
Mit Hilfe dieser Optionen habe ich die Benchmarks erneut laufen lassen – und die Ergebnisse waren erneut durchaus interessant.
Zunächst einmal die Insert-Operationen bei 10 Threads für 300.000 Dokumente:
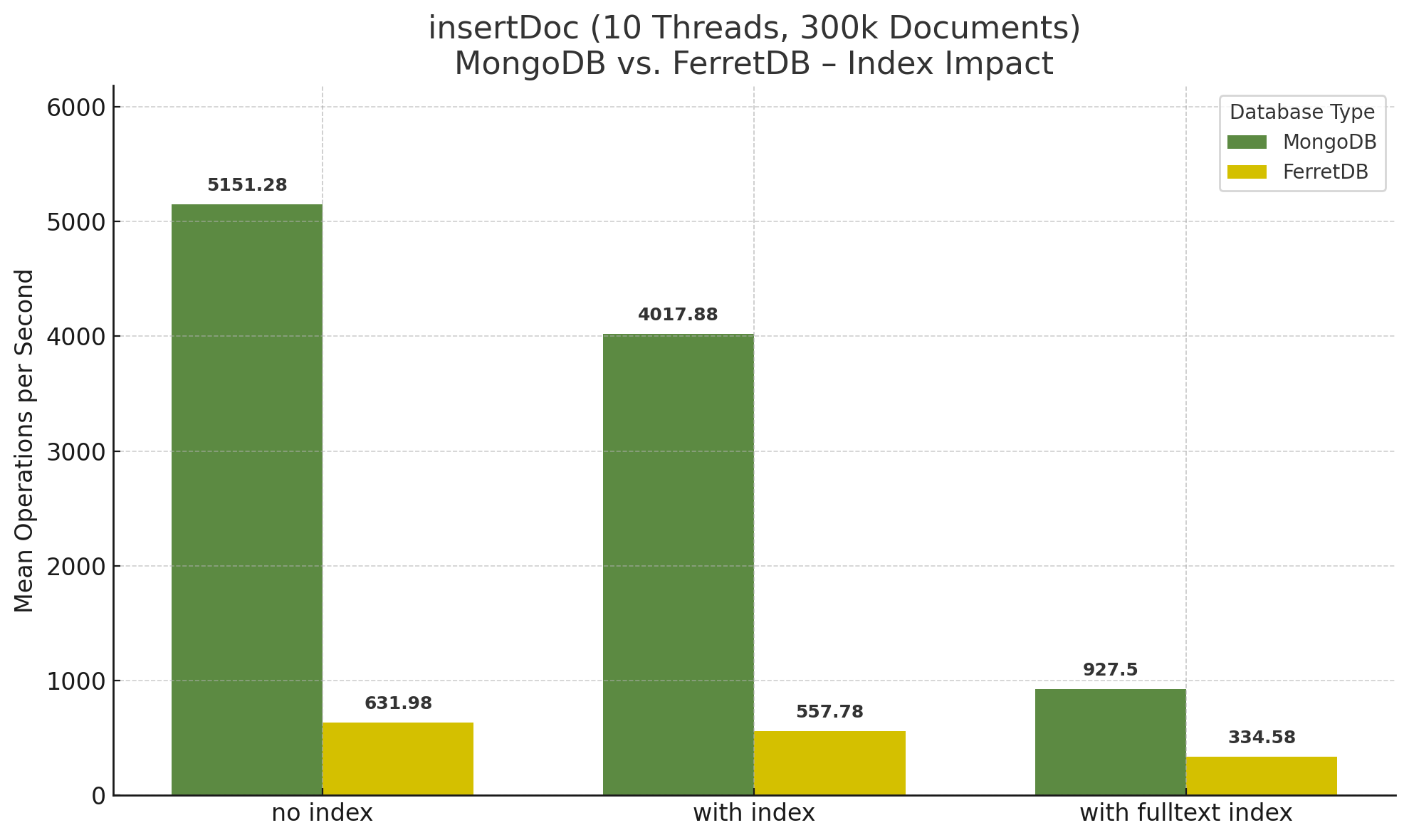
Hier zeigt sich deutlich der Einfluss des Volltext-Index bei MongoDB. Ohne Index ist die Geschwindigkeit hoch, mit vier Indizes, aber ohne Volltext-Index zwar ein wenig geringer, aber bleibt auch im Zeitverlauf in etwa gleich, während sich beim Hinzufügen des Volltext-Index zeigt, dass die Anzahl Operationen pro Sekunde immer weiter abnimmt, je mehr Dokumente gespeichert werden. Der dazu gehörige Verlauf sieht wie folgt aus:
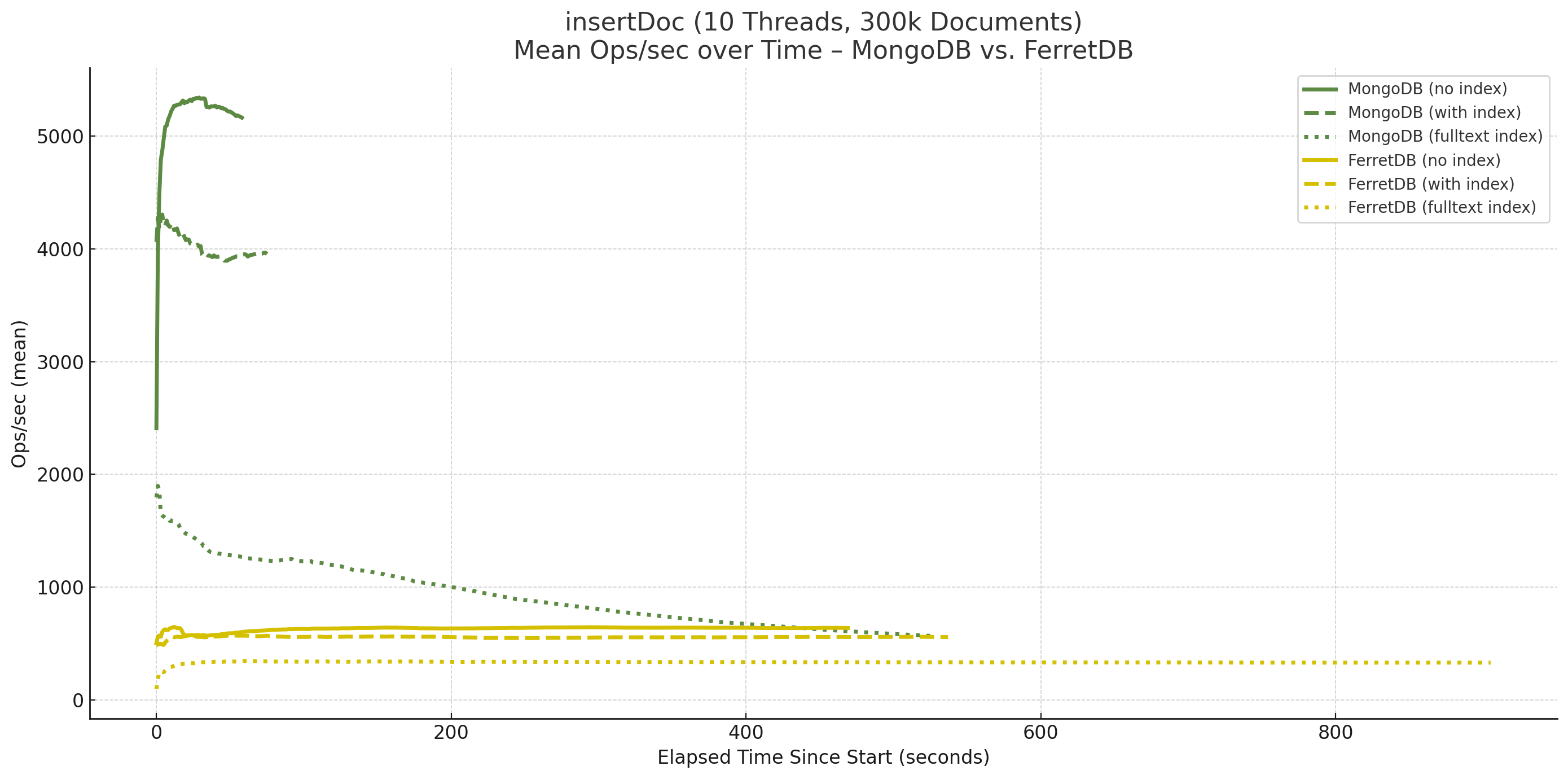
FerretDB hingegen bleibt im Zeitverlauf in etwa gleich, wobei der Volltext-Index auch hier deutlichen Einfluss hat, da gegenüber den Insert-Operationen ohne Index nur noch etwa die Hälfte pro Sekunde gespeichert werden.
Bei 30 Threads zeigen sich wieder die unterschiedlichen Verhaltensweisen von MongoDB und FerretDB. Während FerretDB mit einer im Vergleich zu 10 Threads höheren Anzahl an Operationen pro Sekunde beim Insert ohne Index sowie mit Index außer Volltext ins Rennen geht, bleibt MongoDB bei Verwendung der Indizes ohne Volltext nahezu gleich.
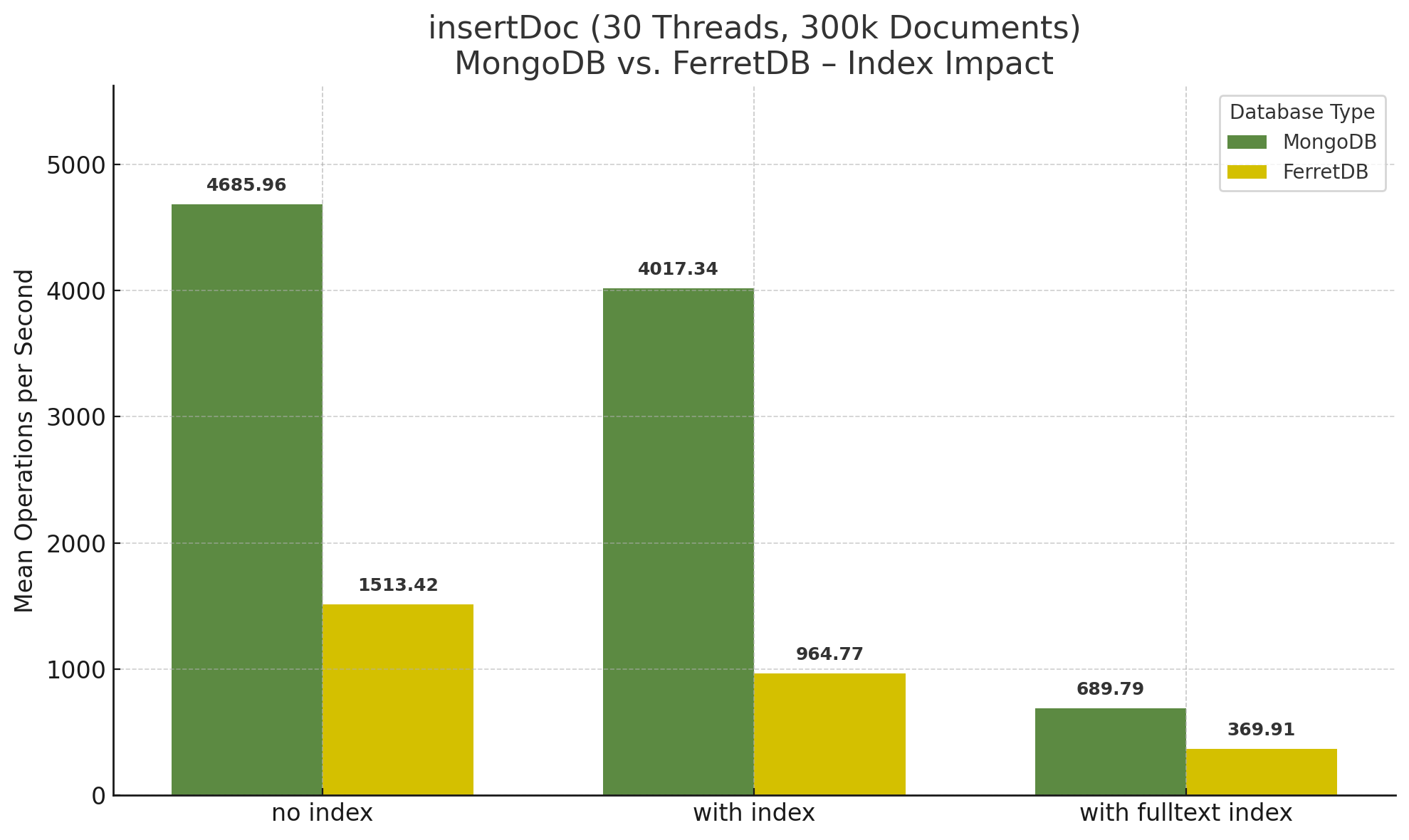
Mit Volltext-Index ist FerretDB zwar bei 30 Threads nur noch geringfügig schneller als bei 10 Threads, es zeigt jedoch erneut insgesamt über die Zeit einen stabilen Verlauf, während MongoDB abermals einbricht:
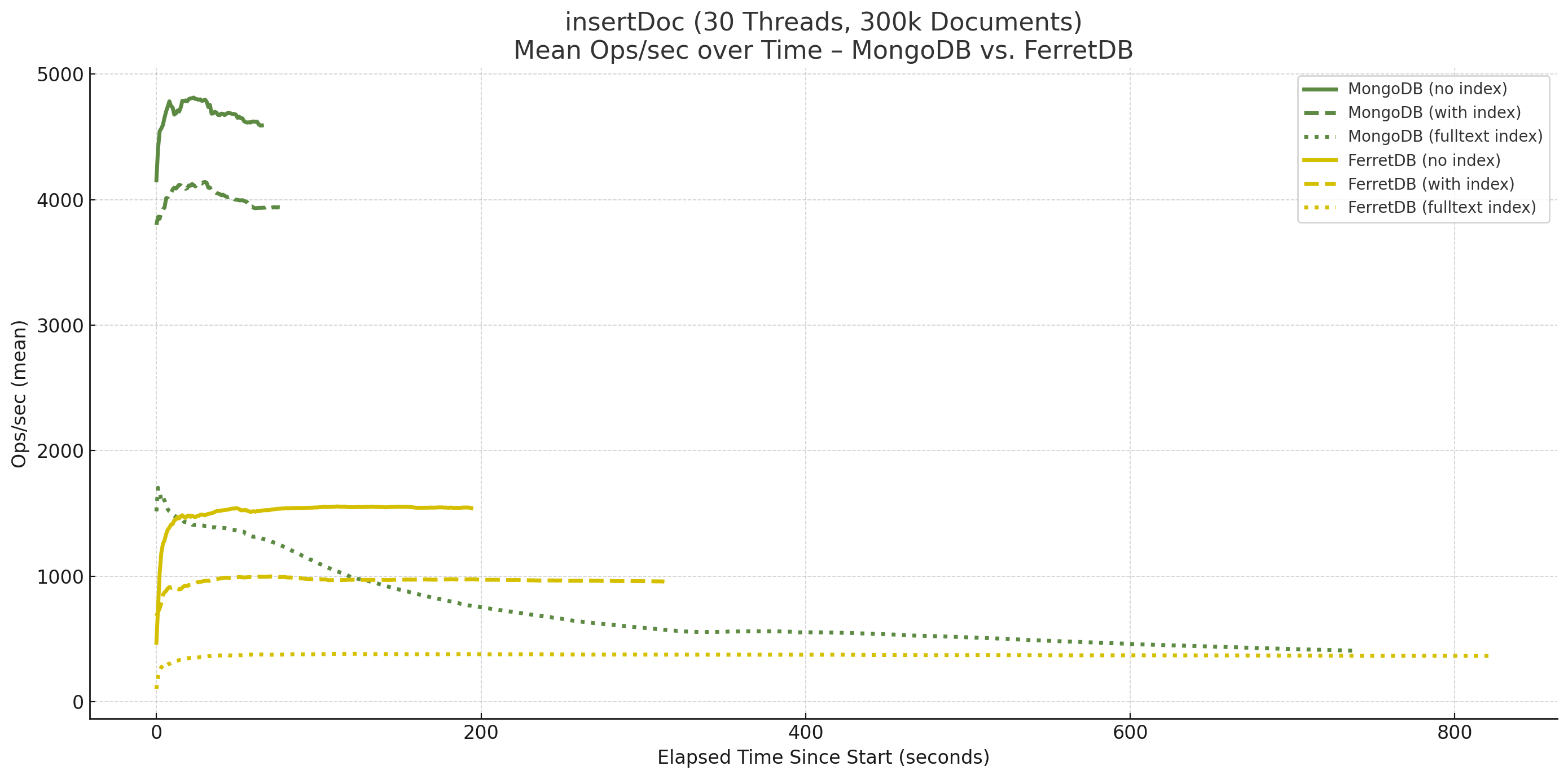
Nun zu den Find-Operationen für die neuen Benchmark-Läufe, zunächst die Ergebnisse ohne Index, dafür mit Augenmerk auf dem Unterschied des gesetzten Limits. Der Benchmark wurde wiederholt mit der bisherigen Einstellung, d.h. Limit 10, aber ergänzt durch die Option Limit 1, so dass nur das erste gefundene Dokument aus der Datenbank gelesen wurde.

Insbesondere bei FerretDB zeigt sich der extrem große Einfluss der Limit-Einstellung bei den bisherigen Queries, d.h. bei allen außer Query 2, wobei diese Abfrage nach 10.000 „guests“ im ersten Benchmark noch nicht durchgeführt worden war (siehe Tabelle weiter oben).
Bei 30 Threads ohne Index ergibt sich ein ähnliches Bild:

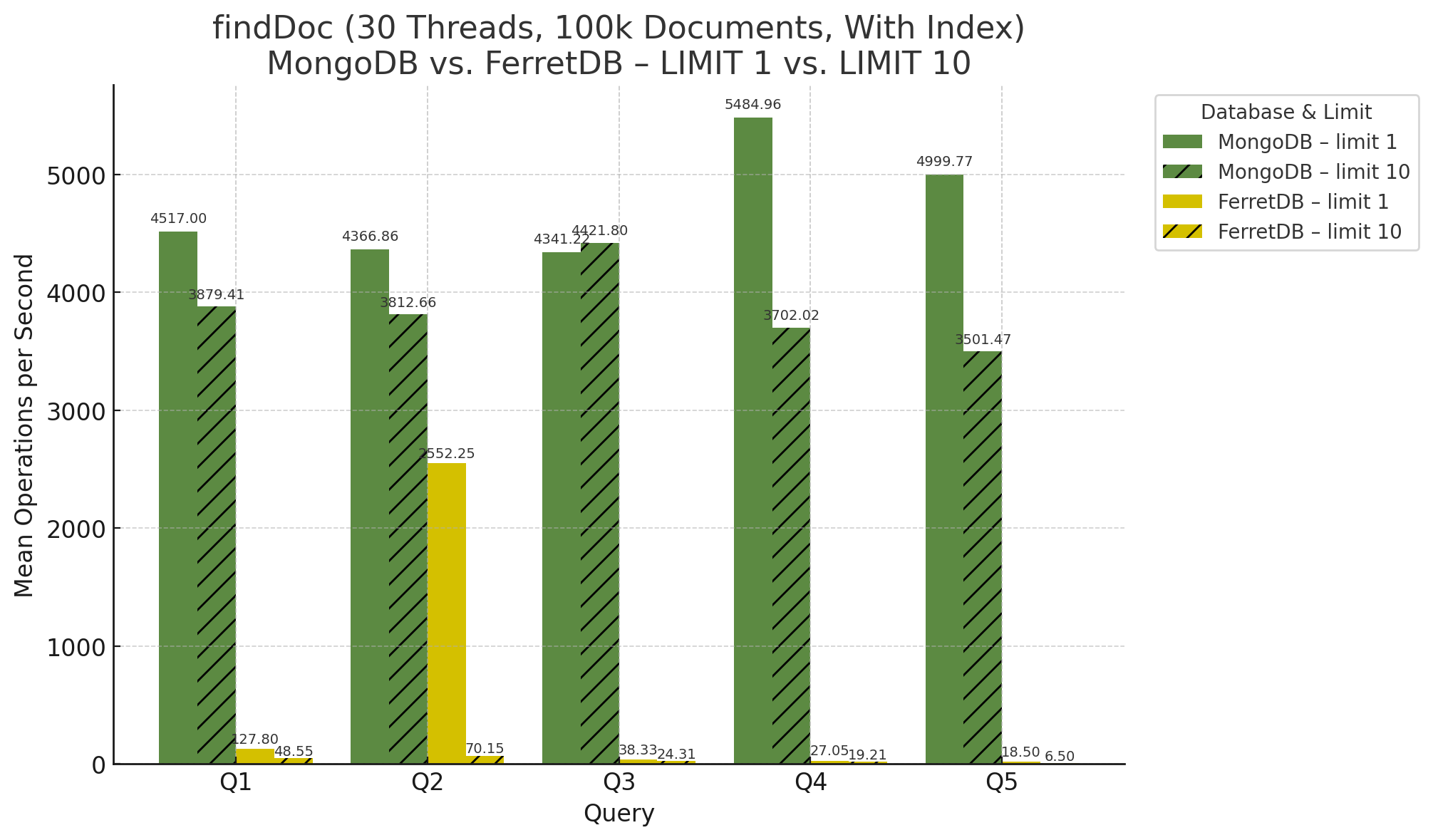
Mit Indizes wurden nun fünf Queries ausgeführt, die sich im Diagramm bei 10 Threads wie folgt zeigen:
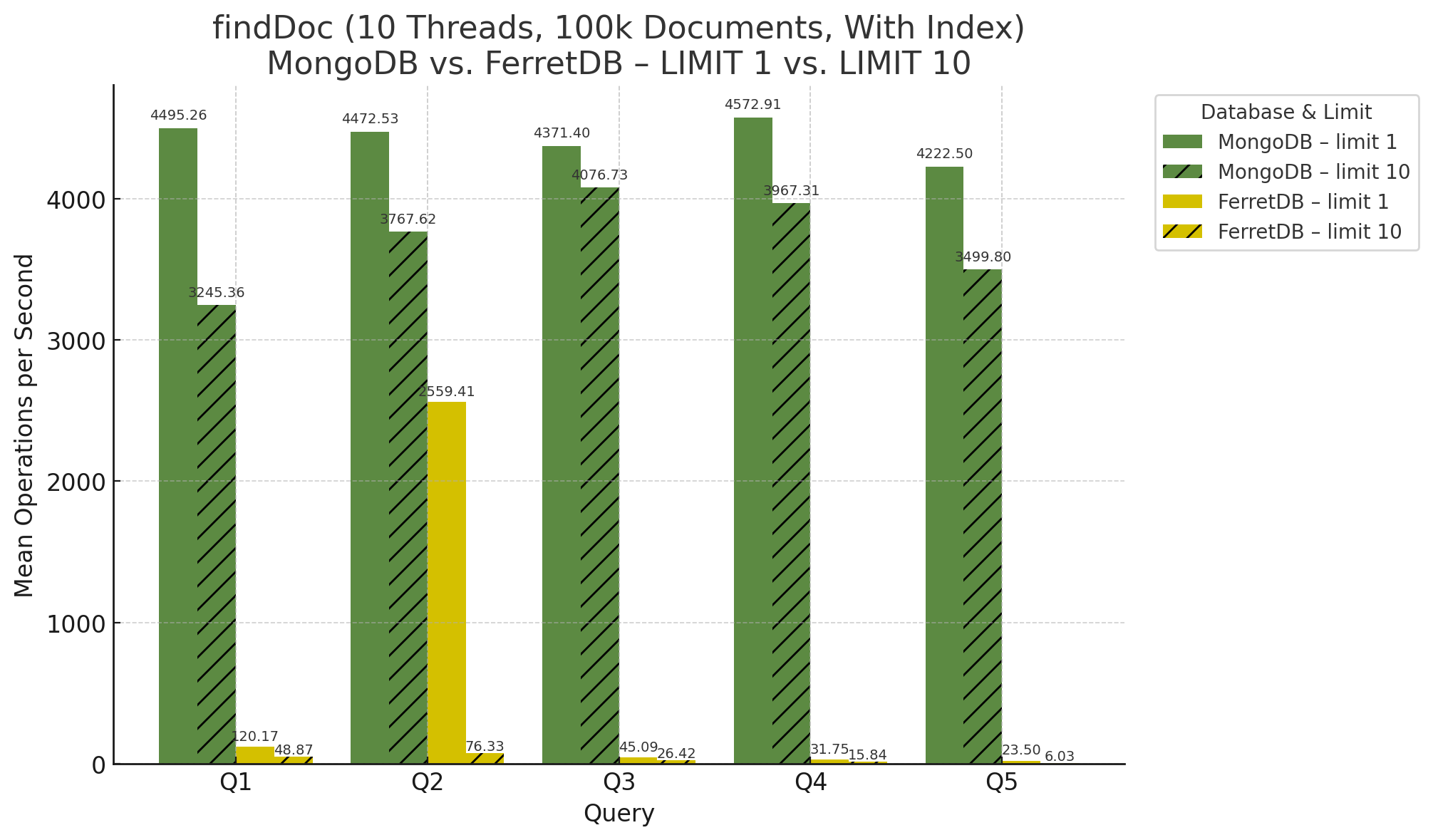
Für 30 Threads ergibt sich dieses Diagramm:
Von FerretDB 2.1 zu Benchmark Teil 3
Und wie der Zufall es so wollte, während all der Benchmark-Läufe und Änderungen am Quellcode des Benchmarks ist – von mir zunächst unbemerkt – eine neue Version 2.1 von FerretDB erschienen. Insbesondere weisen die Autoren darauf hin, dass ein Problem im Zusammenhang mit der Indizierung behoben wurde, so dass Index-Operationen jetzt zuverlässiger und effizienter ablaufen sollen. Natürlich wollte ich dies gleich mal testen, habe dafür sogleich die neue Version installiert und die Benchmarks erneut laufen lassen. Selbstverständlich ohne irgendwelche Altlasten, sondern ausschließlich mit neuen Versionen und neu generierten Daten, wobei ich mich auf die Benchmarks mit Index beschränkt habe.
Im Vergleich zeigen sich FerretDB 2.0 und 2.1 wie folgt, zunächst die Find-Operationen bei 10 Threads:

Nicht viel anders ist das Diagramm für 30 Threads:

Damit bleibt festzustellen, dass bei den ersten beiden Queries, d.h. die Suche nach „author“ (zufällige Verteilung von 10 Namen) und „guest“ (10.000) die Version 2.1 eine 20 – 25%ige Steigerung der Geschwindigkeit vorhanden ist, dies gilt aber nur für das Limit 1. Wurde das Limit auf 10 gesetzt sowie den anderen Queries ist hingegen kaum ein Unterschied messbar bzw. dieser dürfte im nicht signifikanten Toleranzbereich liegen. Leider ist auch die Volltext-Suche nicht schneller geworden, hier bleibt auf alle Fälle einiges Entwicklungspotenzial.
Fazit und Bewertung – der Blafasel zum Schluss
Zu guter Letzt ein kleines Fazit, wobei sich meine Meinung grundsätzlich nicht von der Bewertung des letzten Artikels unterscheidet. Die Messungen mit dem Versuch von „realistischen“ Dokumenten förderte jedoch einige Unterschiede zutage, etwa dass MongoDB beim Einfügen von Dokumenten mit Volltext-Index letztlich auch seine eigenen Schwierigkeiten hat. Interessant sind auch die Differenzen beim Vergleich von Limit 1 vs. Limit 10 bei FerretDB. Dass die Find-Operationen beim Lesen von 10 Dokumenten langsamer als bei einem sind, dürfte noch intuitiv erklärbar sein, aber hier zeigen sich überproportionale Einbußen bzw. Steigerungen.
Insgesamt würde ich die Ergebnisse dahingehend interpretieren, dass bei der Verwendung von FerretDB den Daten bzw. der Dokument-Struktur sowie dem Aufbau der Indizes wesentlich mehr Beachtung geschenkt werden muss als bei MongoDB. Noch dazu dürfte MongoDB auch ohne Indizes häufig einfach „schnell genug“ sein, so dass etwaige Engpässe wesentlich später auffallen und vorab nicht unbedingt eine Lösung oder Optimierung verlangen. Der Benchmark berücksichtigt beispielsweise noch gar keine zusammengesetzten Indizes oder eine Sortierung bei den Find-Operationen, beides wäre definitiv eine genauere Betrachtung wert.
Insofern wären wir auch wieder beim Anfang des Artikels – und der Analogie zur Aussage bzgl. Statistiken. In meinem kleinen aktuellen Projekt werde ich jedenfalls FerretDB gerne weiterhin einsetzen und bin durchaus gespannt, wie es sich in dieser dann tatsächlich realen Anwendung zukünftig schlägt.


 im Heimnetz mit pfSense")