
Das schwarze Loch für die Internet-Reklame – so nennt sich Pi-hole, zugegebenermaßen etwas frei übersetzt. In diesem Artikel möchte ich die Konfiguration von Pi-hole beschreiben, wie sie seit einigen Wochen im heimischen Netzwerk eingerichtet ist. Dabei gehe ich vom vorherigen Status aus und zeige den Weg zum hochverfügbaren Betrieb von Pi-hole mit Hilfe von Keepalived, einer „floating IP“ und natürlich Docker.
Im ersten Teil dieses Artikels werde ich den Weg vom Status quo zur finalen Lösung skizzieren und auf die verwendeten Komponenten sowie deren Verwendung eingehen. Der zweite Teil beschreibt schließlich die Konfiguration im Detail, darin werden sich insofern auch entsprechende Konfigurationsdateien und einige Skripte finden.
Pi-hole von oben – eine Übersicht
Pi-hole ist ein Paket aus verschiedenen Programmen, die letztlich einen DNS-Server bereit stellen. Wird dieser DNS-Server im Netzwerk genutzt, werden Anfragen an diejenigen Domains blockiert, von denen bekannt ist, dass sie zur Auslieferung von Werbung genutzt werden. Das führt dazu, dass Werbung effektiv blockiert wird, denn für den Fall, dass der Browser versucht, eine entsprechende Werbe-Domain zu erreichen, wird vom DNS-Server einfach zurück gegeben, dass diese Domain nicht existiert, insofern kann auch keine Werbung ausgeliefert werden. Pi-hole blockiert laut eigenen Angaben über 100.000 bekannte Werbe-Domains, aktuell sind es sogar noch weitaus mehr, die Listen werden von der Community bereit gestellt und regelmäßig aktualisiert.
Zugegebenermaßen war ich anfangs skeptisch, nicht zuletzt klingelte immer der Zensur-Teufel im Hinterkopf, aber dennoch wollte ich Pi-hole zumindest einmal ausprobieren und war schnell überzeugt. Einerseits lassen sich eigene White- sowie Blacklists pflegen, d.h. falls doch einmal eine Domain zu viel oder zu wenig blockiert werden sollte, lässt sich dies leicht beheben. Auch für Adblocker-Blocker und deren Gehilfen ist mitunter ein Eintrag auf der Whitelist notwendig. Andererseits funktionieren die Listen erstaunlich gut, womit sich wiederum die jeweils im Browser installierten Adblocker einsparen lassen, denn letztlich stellen diese dieselbe Funktionalität bereit, nur eben nicht zentral im Netzwerk, sondern für jeden Browser einzeln. Der große Vorteil von Pi-hole ist, dass es an zentraler Stelle im Netzwerk agiert und somit auch (Werbe-)Requests aller angeschlossenen Geräte erfasst, etwa Amazon Echo in all seinen Inkarnationen, den diversen Servern mit entsprechende Software, und natürlich nicht zuletzt Handys, Tablets etc.. Pi-hole besitzt ein sehr schmuckes web-basiertes Admin-Interface, das einem neben einem Dashboard auch einen tieferen Einblick in die DNS-Anfragen bietet.
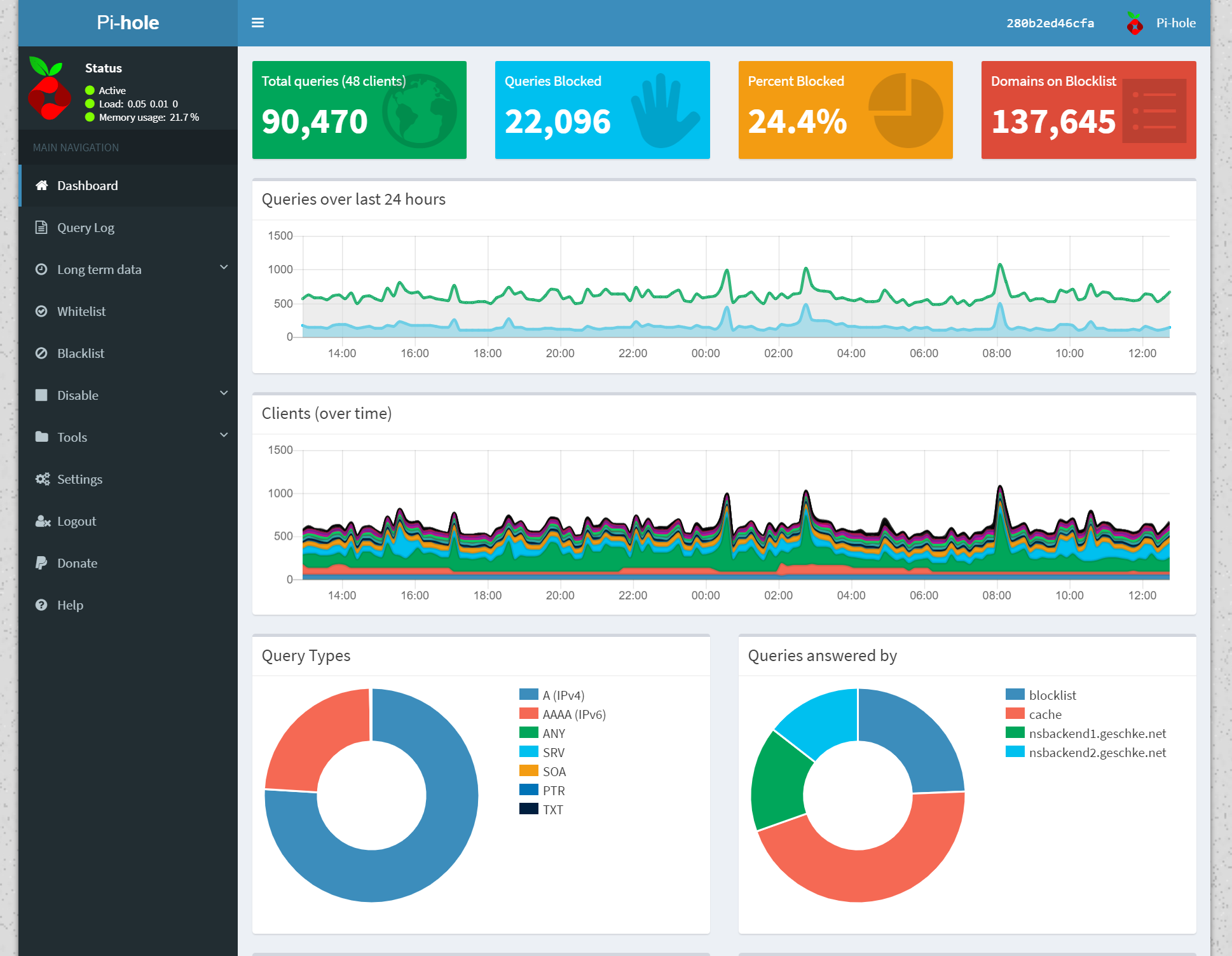
Tatsächlich war ich nach wenigen Tagen Probebetrieb durchaus erstaunt, wie viele und vor allem welche DNS-Anfragen stattfinden – und zwar nicht nur an diejenigen Sites, die Pi-hole blockiert, sondern auch völlig reguläre Anfragen, die von Pi-hole korrekt beantwortet werden. Eine Live-Beobachtung der letzten Anfragen kann durchaus spannend sein… Das Admin-Interface war ein wesentlicher Aspekt, der mich überzeugt hat, Pi-hole einsetzen zu wollen. Insofern kann ich nur jedem empfehlen, Pi-hole einmal selbst auszuprobieren und dann zu entscheiden, ob die Nutzung sinnvoll erscheint oder nicht.
Wie der Name Pi-hole nahe legt, funktioniert das System auch auf einem Raspberry Pi Kleinstrechner. Tatsächlich sollte eine derartige Infrastruktur auch in den meisten Fällen ausreichen, insbesondere für den Betrieb im heimischen Netzwerk. Doch da ich bereits konventionelle DNS-Server eingesetzt habe, war der Raspberry Pi für mich keine sinnvolle Option. Statt dessen wollte ich die bisherige Infrastruktur einer gründlichen Renovierung unterziehen – oder vielmehr einem Abriss und Wiederaufbau.
Zwei DNS-Server fürs Netz
Die klassische Struktur findet sich in folgender Übersicht:
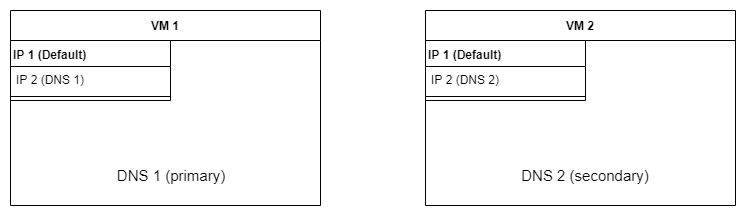
Es handelt sich um zwei virtuelle Maschinen (VM), die auf zwei unterschiedlichen Hosts eingerichtet sind. Sie besitzen jeweils zwei IP-Adressen – eine Standard-IP-Adresse, mit der sie im Netzwerk bekannt sind, und eine speziell für den DNS-Server. Für den Fall, dass die DNS-Server-Software auf andere VMs umgezogen werden sollte, kann die IP-Adresse des DNS-Servers beibehalten werden, indem sie einfach als zweite IP-Adresse auf dem neuen Server eingerichtet wird. Somit ist keine Änderung der DNS-IP-Adressen innerhalb der Clients notwendig – wozu ich auch Router o.ä. zähle, die letztlich die DNS-IP-Adressen per DHCP weitergeben oder als Proxy fungieren.
Die DNS-Server-Software BIND ist dabei klassisch als Daemon eingerichtet, die Daten werden automatisch bei Änderung auf dem Primary DNS vom Secondary DNS übernommen. Der entscheidende Grund, überhaupt eigene DNS-Server zu betreiben, liegt in meinem Nutzungsszenario – meine „lokale“ Domain geschke.net existiert auch im weiten Internet da draußen. Das hat den Vorteil, dass ich lokal bzw. im Netzwerk mit einer „echten“ Domain testen und entwickeln kann bzw. nicht mit Vehikeln wie .local oder ähnlichen Pseudo-Domains agieren muss. Innerhalb des lokalen Netzwerks lassen sich somit Domains definieren, die direkt von den eigenen DNS-Servern beantwortet werden, somit kann ich allen VMs bzw. Maschinen im Netzwerk IP-Adressen aus dem privaten Adressbereich zuweisen und sie unter ihrem Namen ansprechen. Alle DNS-Anfragen, die über die lokal verwendeten Domains hinaus gehen, werden an andere DNS-Server weiter geleitet, was nichts anderes ist, als wenn der Client direkt die z.B. vom Provider, Google oder anderen Institutionen bereit gestellten DNS-Server nutzen würde, nur dass die Anfrage eben von einem der heimischen DNS-Server kommt.
Da DNS-Server so eminent wichtig sind, sind diese bereits per Default ausfallsicher angelegt. Wobei – bezüglich dieser Definition lässt sich prima diskutieren, an dieser Stelle ist es jedoch eher relevant, darauf hinzuweisen, dass jeder Client die Möglichkeit bietet, mehrere DNS-Server einzutragen. Falls einer nicht erreichbar ist, wird versucht, den nächsten zu erreichen. Und die DNS-Server-Software wiederum erlaubt die Unterscheidung in Primary und Secondary, wobei die als Secondary bzw. Slave deklarierten Server die Änderungen vom Primary bzw. Master per Zonentransfer übernehmen. Danach besitzen beide DNS-Server identische Datenbestände und können Anfragen beantworten.
Diese Funktionalität wollte ich auch beim Einsatz von Pi-hole nicht missen, denn falls etwa zu Wartungszwecken einmal einer der VMs oder gar der Host abgeschaltet werden muss, sollen die Clients auch weiterhin DNS nutzen können, ansonsten wäre der komplette Betrieb nahezu lahm gelegt. Letztlich wurde es jedoch eine andere Art von Ausfallsicherheit, dazu gleich mehr.
Einsatz von Pi-hole – Vorüberlegungen
Um zu verstehen, weshalb ich mich für die gleich vorgestellte neue Struktur entschieden habe, müssen ein paar Vorüberlegungen getroffen werden. Diese beziehen sich auf die Datenhaltung und Praktikabilität der Admin-UI-Nutzung.
Pi-hole Daten und Datenbank
Wie bereits erwähnt, bedient sich Pi-hole mehrerer Listen von Domains, anhand der das Matching von Ad-relevanten Domains erfolgt. Darüber hinaus müssen eigene Black- und Whitelists gespeichert werden. Zur Bereitstellung der Statistiken im Pi-hole-Web-Interface werden die DNS-Requests getrackt und in einer SQLite-Datenbank abgelegt. Dabei ist der SQLite-Code Bestandteil der zentralen Komponente FTLDNS von Pi-hole. FTLDNS beantwortet jedoch nicht nur DNS-Anfragen, sondern dient auch als API für das Web-Interface. SQLite ist jedoch kein klassischer Datenbank-Server, der Anfragen von Clients entgegen nimmt und etwa Transaktionssicherheit bietet, sondern darf als eingebettete SQL-Library gelten, die ihren Fokus nicht darauf hat, parallele Schreibzugriffe zu ermöglichen. Im Gegenzug ist SQLite schnell, klein, unkompliziert, ausgereift und für den ursprünglichen Einsatzzweck – man bedenke den Raspberry Pi – sehr gut geeignet, da der Overhead eines kompletten Datenbankverwaltungssystems entfällt. Das führt direkt zum zweiten Punkt.
Nutzung der Admin-UI
Standardmäßig speichert Pi-hole alle notwendigen Daten, d.h. Listen, Konfiguration und die Datenbank-Datei in einem Verzeichnis. Gesetzt den Fall, man würde mehrere Pi-hole-Systeme gleichzeitig betreiben, müssten diese entweder auf ein gemeinsames Verzeichnis zurück greifen oder aber jeweils ein eigenes, lokales Verzeichnis besitzen. Beides hat seine Nachteile.
Je nach Client lässt sich nicht vorher sagen, welcher DNS-Server, d.h. ob primary oder secondary genutzt wird. Es ist also nicht festgelegt, dass zunächst der erste, und nur im Fehlerfall der zweite angefragt wird. Beispielsweise ist die Verteilung laut Pi-hole-Dashboard, d.h. der Nutzung der Upstream-DNS-Server nahezu gleich. Wenn nun zwei Pi-hole-Instanzen auf ein gemeinsames Verzeichnis zugreifen würden, und jede Instanz z.B. autark die Listen aktualisiert bzw. auf die SQLite-Datenbank zugreift, kommt es früher oder später zu Konflikten, die vermutlich das Schreddern einiger Daten zur Folge haben würden. Zwar lässt sich der parallele Zugriff auch mit der vorgestellten Struktur nicht unter allen Umständen vermeiden, aber die Gefahr zumindest entschärfen.
Wenn hingegen mehrere Pi-hole-Instanzen jeweils auf eigene Daten-Verzeichnisse zurück greifen würden, hätte man auch zwei Admin-Interfaces mit jeweils unterschiedlichen Angaben, zwei Stellen, an denen Black- und Whitelist gepflegt werden müssten usw.. Insbesondere die Nutzung der Admin-UI legt es also nahe, dass es einen „Single Point of Truth“ geben sollte, der die gesamte Sicht auf die Datenhaltung widerspiegelt.
Performance der DNS-Requests
Wenn selbst ein kleiner Raspberry Pi für die Beantwortung von DNS-Anfragen im Netzwerk ausreicht, sollte das doch erst recht für eine VM gelten, auf der nichts anderes als ein DNS-Server und Pi-hole läuft. Insofern würde auch ein einziger DNS-Server genügen, vorausgesetzt, dieser ist immer erreichbar bzw. es werden Maßnahmen zur Ausfallsicherheit getroffen. Tatsächlich ist die Performance kein Problem. In den ersten Tests ergaben sich innerhalb von 24 Stunden weit über 100.000 DNS-Requests, die von Pi-hole beantwortet wurden, durchschnittlich sind es im regulären Betrieb knapp unter 100.000 pro Tag. Manche Konfiguration verursacht im Fehlerfall sehr viele DNS-Requests, doch Pi-hole war jederzeit in der Lage, damit zurecht zu kommen.
Das Ergebnis dieser Überlegungen lässt sich somit zusammenfassen:
- Die Datenhaltung (Listen, Konfiguration, Datenbank) soll aufgrund der Struktur und der von Pi-hole eingesetzten Komponenten an nur einer Stelle erfolgen.
- Eine Pi-hole-Instanz, d.h. ein mit Pi-hole bestückter DNS-Server ist ausreichend.
- Es müssen Maßnahmen zur Sicherstellung des Betriebs im Fehler- oder Wartungsfall getroffen werden – Stichwort Ausfallsicherheit.
Der Wiederaufbau mit neuer Infrastruktur
Dies führt zur folgenden neuen Struktur, hier in der Übersicht:
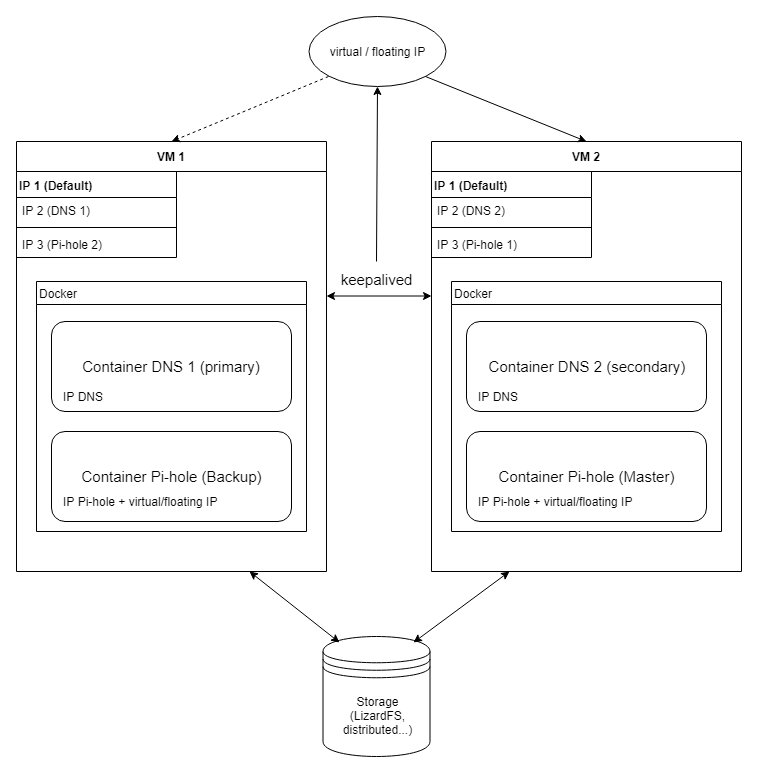
Im Folgenden einige Erläuterungen zu dieser Lösung – von oben nach unten betrachtet.
Floating IP
Eine Floating IP – oder auch virtuelle IP-Adresse – kann flexibel einer von mehreren VMs bzw. allgemein Nodes zugewiesen werden. Je nach Verfügbarkeit kann die IP-Adresse somit im konkreten Fall entweder zur ersten virtuellen Maschine (VM1) oder zur zweiten (VM2) gehören. Die IP-Adresse wird dabei nicht innerhalb der Netzwerk-Konfiguration fest definiert, sondern vom Keepalive-Daemon (Keepalived) auf beiden VMs verwaltet und mittels Virtual Router Redundancy Protocol (VRRP) einem Node zugewiesen. Das Ziel ist somit, nur eine IP-Adresse für den DNS-Server zu verwenden, die in den Clients bzw. im Router eingetragen wird. Fällt der aktive Node aus oder kommt es zu Problemen, sorgt Keepalived dafür, dass die IP-Adresse dem anderen Node zugewiesen wird. Danach kann Keepalived weitere Aktionen ausführen, im konkreten Fall wird ein Skript angesteuert, das wiederum dafür zuständig ist, die zweite Pi-hole-Instanz bzw. dessen Docker-Container zu starten.
Damit wäre auch bereits das Grundkonzept der angestrebten Lösung dargelegt: Ein Pi-hole-Container läuft auf einem Master genannten Node, wobei Node hier analog zu VM zu verstehen ist. Alle Clients erreichen den DNS-Server über eine IP-Adresse, und nur diese wird von den Clients genutzt. Der Status der beiden Nodes wird durch Keepalived überwacht, bei Ausfall wird die IP-Adresse auf den Backup-Node gelegt, so dass die DNS-Anfragen dort ankommen. Ist der Master wieder verfügbar, sorgt Keepalived ebenfalls dafür, dass die Floating IP wieder zurück marschiert.
Master und Backup sind insofern keine gleichberechtigten Nodes im Netzwerk, was eine gewisse Analogie zum DNS-Server an sich und deren Handhabung als Primary und Secondary darstellt.
Mehrere IP-Adressen
Die VMs besitzen erneut, d.h. wie im eingangs erwähnten Status quo, mehrere IP-Adressen. Dabei handelt es sich neben der Default-IP im Netzwerk um eine IP-Adresse, die für den DNS-Server reserviert wird, was einen Umzug auf eine andere VM erleichtert. Dasselbe Konzept gilt für die Adressen der DNS-Server, die von Pi-hole bereit gestellt werden, die ebenfalls einen festen Wert besitzen. Daneben soll Pi-hole wie beschrieben über die Floating IP angesprochen werden können, dazu bedarf es allerdings nur einer Anpassung der Konfiguration im Docker-Startkommando. Es mag auf den ersten Blick ein wenig überdimensioniert erscheinen, aber auf diese Art und Weise bleibt alle Flexibilität der Nutzung der DNS-Server erhalten. Beispielsweise gibt es Fälle, in denen man Werbeeinblendungen sehen möchte, etwa als Test, ob die Ads auf den eigenen Web-Seiten funktioniert. Eine Möglichkeit wäre, innerhalb von Pi-Hole eine Whitelist zu pflegen, doch diese würde sich auf alle angeschlossenen Clients auswirken. Besser wäre es, wenn die DNS-Server ohne Pi-hole genutzt werden könnten, und genau das ist mit dieser Struktur möglich.
Zusammengefasst ergibt sich folgende Tabelle:
| IP alt | Verwendung | IP neu | Verwendung |
| 192.168.10.38 | IP der VM | 192.168.10.38 | IP der VM 1 |
| 192.168.10.52 | IP der VM | 192.168.10.52 | IP der VM 2 |
| 192.168.10.20 | Primary DNS | 192.168.10.20 | Pi-holed DNS (Backup) |
| 192.168.10.21 | Secondary DNS | 192.168.10.21 | Pi-holed DNS (Master) |
| 192.168.10.220 | Primary DNS (ohne Pi-hole) | ||
| 192.168.10.221 | Secondary DNS (ohne Pi-hole) | ||
| 192.168.10.19 | Floating IP Pi-holed DNS |
Hinweis: Da der Host, auf dem der Secondary DNS betrieben wird, leistungfähiger ist, habe ich den Master von Pi-hole auf den Node vom Secondary DNS Container gelegt und umgekehrt. Da die IP-Adressen von Pi-hole jedoch eigentlich nicht direkt verwendet werden sollen, sondern ausschließlich die Floating IP, ist dies allenfalls anfangs verwirrend, für den Betrieb vom technischen Aspekt her jedoch irrelevant.
Docker für alle(s)
Oder vielmehr fast alles. Da ich bereits „dockerized“ DNS-Server betreibe, sollte das Docker-Image auch diesmal zum Einsatz kommen. Zwar ein wenig entgegen des Konzepts von Docker, pro Image bzw. Container nur einen Service bereit zu stellen, beinhaltet das Docker Container Image for BIND DNS auch eine Webmin-Instanz zur einfacheren Einrichtung der DNS-Daten. Um Missverständnissen vorzubeugen – auch dabei muss man darauf achten, dass die DNS-Einträge korrekt sind, denn man kann sich in etwa genauso mächtig in den Fuß schießen wie bei der Einrichtung von BIND auf der Kommandozeile. Aber wenn die Web-UI quasi kostenlos „aus der Tüte fällt“, spricht auf nichts dagegen, sie zu verwenden.
Ebenfalls sollte Pi-hole als Docker-Container betrieben werden, das entsprechende Image wird nicht zuletzt von den Entwicklern als eine von zwei Installationsmethoden propagiert. Insofern nutze ich auch genau dieses Docker-Image, das alle Komponenten inklusive der Admin-UI beinhaltet. Dabei wird unter anderem die Floating IP an den Pi-hole-Docker-Container gebunden, so dass der Pi-holed DNS-Server unter dieser einen IP erreichbar ist. Im Optimalfall läuft zu einer beliebigen Zeit nur jeweils ein Pi-hole-Container auf einer der beiden VMs, gesteuert durch Keepalived.
Keepalived selbst habe ich hingegen nicht in Docker-Images gepackt. Denn in diesem Fall sehe ich keine Vorteile – Keepalived ist schnell eingerichtet, ist im Lieferumfang der gängigen Linux-Distributionen enthalten, aber der entscheidende Punkt ist, dass es eine sehr systemnahe Komponente ist, die immerhin die IP-Adresse des jeweiligen Hosts anpassen muss, dafür auch die entsprechenden Rechte benötigt usw., so dass ich die etwaigen durch den Einsatz von Docker induzierten Probleme gerne vermeiden wollte. Ein Docker-Keepalived-Image habe ich immerhin gefunden, was auch aktualisiert und gepflegt wird, vielleicht lohnt sich hier ein näherer Blick.
(verteiltes) Storage
Als Storage-Schicht fungiert in der angestrebten Lösung ein verteiltes Dateisystem. Dazu wird LizardFS genutzt, das seit einiger Zeit, genau genommen einige Monate (relativ) problemlos auf mehreren VMs läuft. LizardFS wird von den beiden VMs gemountet und steht somit direkt nach dem Booten zur Verfügung. Im von LizardFS bereit gestellten Verzeichnis befinden sich die eingangs erwähnten Verzeichnisse für Konfigurationsdateien, Listen und der SQLite-Datenbank von Pi-hole. Dem gegenüber kommen die BIND-DNS-Container ohne eine gemeinsame Dateiablage aus, d.h. die entsprechenden Verzeichnisse mit Zonen-Dateien etc. liegen nur im Dateisystem der VMs und werden beim Start der Docker-Container eingebunden.
Das Thema verteiltes Storage ist sicherlich diskussionswürdig, daher an dieser Stelle einige Hinweise. Im Normalbetrieb läuft das System hervorragend – der Pi-hole-Container aktualisiert Listen, agiert mit der SQLite-Datenbank-Datei usw., die Performance ist ausreichend, insofern ist alles im grünen Bereich. Der Vorteil des verteilten Storage-System ist ebenfalls, dass es keinen Single-Point-of-Failure gibt, LizardFS ist hier anhand seiner Konfiguration redundant ausgelegt, so dass auch dabei eine gewisse Ausfallsicherheit gegeben ist. Zur Konfiguration von LizardFS ließe sich noch weitaus mehr schreiben – wichtig erscheint mir der Punkt, dass es zunächst einmal funktioniert und die Performance wesentlich besser ist als beim zuvor getesteten ebenfalls verteilten Dateisystem GlusterFS.
Dennoch kann es aufgrund der Architektur von Pi-hole zu Problemen kommen, zumindest sollte man sich diesen Überlegungen bewusst sein. Wie weiter oben kurz erwähnt, kann keepalived nicht garantieren, dass zu jedem Zeitpunkt nur eine Instanz von Pi-hole läuft. Das passiert beispielsweise genau dann, wenn keepalived auf einem Node ad hoc nicht mehr funktioniert, insofern abstürzt. Oder wenn keepalived schlicht und einfach mit voller Absicht beendet wird. In diesem Fall läuft der Pi-hole-Container auf der VM weiter, während sich der keepalived auf dem zweiten Node um die Erreichbarkeit kümmert, d.h. die Floating IP auf den zweiten Node bringt und dort den Pi-hole-Container startet. Schon laufen zwei Pi-hole-Container parallel. Keepalived hat seine Aufgabe zwar hervorragend erfüllt, dennoch erfolgt damit der Zugriff zweier Pi-hole-Instanzen auf dieselben Dateien im verteilten Dateisystem. Zwar werden die DNS-Requests beim neu gestarteten Pi-hole-Container landen, aber dennoch könnten beispielsweise mehr oder minder gleichzeitig Listen updated werden. Die Frage lautet, was in solchen Fällen passieren könnte. Im schlimmsten Fall werden die Dateien und ebenso die Datenbank unbrauchbar, geschredderter Datenmüll. Was wäre die Folge? Die von der Community gepflegten Blacklists werden beim nächsten regulären Start von Pi-hole einfach wieder neu geladen, falls sie nicht im Datenverzeichnis existieren – insofern keinerlei Verlust. Die eigenen Black- und Whitelists wären evtl. verloren – hier empfiehlt es sich somit trotz aller Redundanzen, ein Backup anzufertigen. Die Datenbank mit Zugriffen für die Statistik wäre möglicherweise ebenfalls verloren oder es würden zumindest Einträge fehlen. Ich für meinen Fall könnte damit gut leben, schließlich handelt es sich nicht um lebensnotwendige oder unwiederbringliche Daten.
Ebenso stellt sich die Frage, inwieweit man LizardFS überhaupt vertrauen kann oder ob es nicht Alternativen gäbe. Natürlich gibt es die! Wie so oft führen hier viele Wege zum Ziel, von der Nutzung von NFS bis hin zum Ceph-Cluster ist es nur eine Frage des Aufwands, der in den Aufbau der Infrastruktur gesteckt werden soll. Oder man nutzt etwa DRBD, um eine Synchronisation der Dateisysteme zu erreichen. All diese Verfahren unterscheiden sich jedoch nicht vom Konzept her, somit kann es auch zu den beschriebenen Problemen im Worst Case kommen.
Eine weitere Möglichkeit wäre, die Synchronisierung der Listen und SQLite-Datenbank vom Master- auf den Backup-Node manuell bzw. in regelmäßigen Abständen per Cron o.ä. gesteuert, durchzuführen. Beispielsweise könnte alle fünf Minuten ein rsync-Kommando gestartet werden, so dass der Backup-Node regelmäßig mit den aktuellen Daten versorgt wird. Ein Nachteil dieser Methode ist sicherlich, es auch dabei zu Problemen kommen kann – falls Synchronisierung und Ausfall des Master-Nodes zufälligerweise gleichzeitig stattfinden sollten. Zudem würden im Datenbestand des Backup-Nodes auch immer die letzten fünf Minuten fehlen. Und falls der Ausfall des Masters länger dauert, müssten die zwischenzeitlich angefallenen Daten genau dann zurück auf den Master kopiert werden, wenn der Regelbetrieb wieder hergestellt ist. Letztlich obliegt es dem Nutzer, welcher Aufwand einem angemessen erscheint, um Ausfallsicherheit und Konsistenz zu erreichen bzw. inwieweit die Gewichtung aller Faktoren erfolgen sollte.
Ausblick
Das soll für diesen Teil genügen – die Ziele sind festgelegt, die Überlegungen zur Infrastruktur wurden getroffen, somit kann es im nächsten Teil direkt los gehen mit der eigentlichen Konfiguration von Keepalived, den Docker-Images bzw. Containern für DNS BIND sowie natürlich Pi-hole und den Skripten und Einstellungen, die alles erst zusammenhalten und den ausfallsicheren bzw. hochverfügbaren Betrieb ermöglichen. Bis dahin – vielen Dank für die Aufmerksamkeit!
Update
Nach wirklich sehr langer Zeit gibt es nun endlich auch den zweiten Teil, der sich mit der Installation und Konfiguration von keepalived und Pi-hole im Detail beschäftigt.



Moin Ralf,
nutze doch „docker swarm“ in deinem Setup mit zwei oder mehr Hosts. Nach meiner Erfahrung mit „keepalived“ auf den Hosts und einem Pi-hole Container als Service im Swarm bei aktivem GlusterFs oder LizardFs löst das dein Problem mit ggf. gleichzeitig zwei aktiven Pi-hole Instanzen.
Selbst wenn der „VM1/Master/Node1“ ausfällt, auf dem ggf. auch die Pi-hole Instanz läuft, so würde Docker Swarm quasi umgehend und automatisch eine neue Pi-hole Instanz auf „VM2/Slave/Node 2“ hochziehen. Da keepalived dann den Save zum Master macht läuft alles wie gewohnt weiter. Aus meiner Sicht gibt es keine Probleme mit den Daten.
Gruß Jerret
Vielen Dank für die Idee! Tatsächlich habe ich Docker Swarm in einer anderen Umgebung auch in Betrieb, aber bei den beiden DNS-Servern hatte ich es bislang nicht in Erwägung gezogen – vielleicht auch daher, weil ich die beiden DNS-Server auf zwei VMs und somit unabhängig von anderen betreiben wollte. Docker Swarms Raft-Algorithmus setzt für ein Quorum jedoch mindestens drei Nodes voraus, ansonsten hat es sich mit der Fehlertoleranz. Aber die Idee ist auf jeden Fall eine Überlegung wert, man kann ja auch noch einen dritten Node dazu packen. Vielen Dank & Beste Grüße,
Ralf
Hallo,
ich kann den angekündigten 2. Teil nicht finden.
Warum ist dieser nicht auffindbar?
THX
Ganz einfach: Weil ich ihn noch gar nicht geschrieben habe. 🙂 Tatsächlich wollte – nein, vielmehr muss ich mich mit der Installation noch einmal beschäftigen, denn mitunter gibt es noch Hakeligkeiten. Wenn das passiert ist, komme ich vielleicht auch zum zweiten Teil. Sorry, manches auf der Todo-Liste fällt einfach hinten runter, vor allem dann, wenn eine Lösung im täglichen Betrieb stabil läuft, so dass sie nicht weiter auffällig ist.
Beste Grüße,
Ralf