
Es folgt der zweite Teil des kleinen Benchmarks, der ebenfalls mehr oder minder ein bewegtes Ziel darstellt. Die ersten Ergebnisse waren dabei zunächst ein wenig anders als vermutet, letztlich stellte sich die Vermutung nach weiteren Untersuchungen jedoch als richtig heraus, was von den Messergebnissen bestätigt wurde.
Überblick
Im ersten Teil hatte ich zwei Docker-Services, einmal MariaDB und einmal ProxySQL auf demselben Host gestartet. Wenn dazu noch der Container käme, mit dem der Sysbench-Benchmark ausgeführt werden sollte, wäre es eher ein Docker-Swarm-Mode-Benchmark geworden anstatt eines ProxySQL-Benchmarks. Um die Einflüsse von Docker auf MariaDB auszuschließen, habe ich daher MariaDB auf einer anderen VM verwendet. Zwar sollte ProxySQL sowohl innerhalb eines Containers als auch als „normaler“ Dienst laufen, um hier einen Vergleich treffen zu können, aber die Beteiligung von Docker bei MariaDB erschien mir als weniger sinnvoll, vor allem, da auch die verwendete Speicher-Methode, d.h. Volume-Container oder nur ein vom Host gemountetes Verzeichnis, zu Unterschieden in der Performance führt.
Letztlich bestand das Test-Szenario aus folgenden Komponenten:
- MariaDB-Server „moeckern“, MariaDB 10.0.24, installiert aus dem MariaDB-Repository
- Server „connewitz“ mit Docker CE 17.09 für Sysbench und ProxySQL
Das Tool Sysbench sollte innerhalb eines Docker-Containers laufen, dazu habe ich mich der Version von Severalnines bedient.
Vorbereitungen
Zur Vorbereitung wurde eine Datenbank auf dem MariaDB-Server angelegt:
MySQL [dbtest]> create database sbtest; Query OK, 1 row affected (0.00 sec) GRANT ALL PRIVILEGES ON sbtest.* to sbtest@'%' IDENTIFIED BY 'passwort';
Zu Beginn müssen ein paar Test-Tabellen angelegt werden, dieser Schritt sieht mit dem o.g. Docker-Container wie folgt aus:
docker run --name=sb severalnines/sysbench sysbench \ --db-driver=mysql --mysql-table-engine=innodb --oltp-table-size=100000 \ --oltp-tables-count=24 --oltp-test-mode=complex --threads=4 --max-requests=0 \ --mysql-host=moeckern --mysql-port=3306 --mysql-user=sbtest \ --mysql-password=passwort \ /usr/share/sysbench/tests/include/oltp_legacy/parallel_prepare.lua prepare
Zum Benchmark an sich muss erwähnt werden, dass die absoluten Zahlen, d.h. Transactions per Second (tps) oder Queries per Second (qps) gar nicht so interessant waren. Denn dass auf der verwendeten Hardware nicht die Werte realisierbar sind, die den Maschinen ähnlich sind, welche sich aktuell in Rechenzentren befinden, war von vornherein klar. Vielmehr interessierten mich die Unterschiede, die beim Betrieb mit ProxySQL unter verschiedenen Konfigurationen auftreten.
Erste Tests
Die ersten Tests habe ich zunächst manuell ausgeführt im folgenden Stil:
docker run --rm --name=sb severalnines/sysbench sysbench --db-driver=mysql \ --oltp-table-size=100000 --oltp-tables-count=24 --threads=4 --oltp-read-only=on \ --max-time=60 --report-interval=2 --mysql-host=moeckern --mysql-port=3306 \ --mysql-user=sbtest --mysql-password="passwort" \ /usr/share/sysbench/tests/include/oltp_legacy/oltp.lua run
Doch auch dies versprach nur diskrete Werte, da z.B. die Anzahl der Threads fest eingestellt war. Des Weiteren waren die ersten Ergebnisse ein wenig merkwürdig – so schien die Variante, ProxySQL mit Docker zu verwenden, zu einer höheren Anzahl von Transactions bzw. Queries pro Sekunde zu führen im Vergleich mit der Variante ohne Docker? Das war einfach zu wenig plausibel, daher habe ich mich zunächst wieder auf die Suche nach Test-Szenarien von MySQL bzw. MariaDB begeben.
Ein neuer Ansatz
Dabei ist mir ein Benchmark-Test von Percona aufgefallen, bei dem der Overhead durch ProxySQL ermittelt worden war (read-only mode). Dies erschien mir als eine gute Grundlage, den Overhead in verschiedenen Szenarien zu testen.
Daraufhin habe ich die dort verwendeten Skripte ein wenig angepasst und für fünf Szenarien vorbereitet. Das folgende Test-Skript variiert die Anzahl der Threads und startet den Sysbench-Docker-Container, der die Ergebnisse, d.h. Test-Ausgaben in ein Verzeichnis schreibt:
#/bin/sh
HOST="--mysql-host=moeckern"
PORT="--mysql-port=3306"
mkdir -p results
docker run --rm --name=sb severalnines/sysbench sysbench --db-driver=mysql --oltp-table-size=100000 --oltp-tables-count=24 --threads=10 --oltp-read-only=on --max-requests=0 --time=120 --report-interval=5 $HOST $PORT --mysql-user=sbtest --mysql-password="PASSWORT" --mysql-db=sbtest --mysql-ssl=off --rand-type=pareto --rand-init=on /usr/share/sysbench/tests/include/oltp_legacy/oltp.lua run | tee -a results/res.warmup.ro.txt
OUT="res.mariad10.0.intel-driver"
mkdir -p results/res-OLTP10t/$OUT
for i in 1 2 3 4 5 6 8 10 13 16 20 25 31 38 46 56 68 82 100
# 120 145 175 210 250 300 360 430 520 630 750 870 1000
do
time=120
docker run --rm --name=sb --volume results:/results severalnines/sysbench sysbench --db-driver=mysql --oltp-table-size=100000 --oltp-tables-count=24 --threads=${i} --oltp-read-only=on --max-requests=0 --time=$time --report-interval=5 $HOST $PORT --mysql-user=sbtest --mysql-password="PASSWORT" --mysql-db=sbtest --mysql-ssl=off --rand-type=pareto --rand-init=on --forced-shutdown=1 --mysql-ssl=off /usr/share/sysbench/tests/include/oltp_legacy/oltp.lua run | tee -a results/res-OLTP10t/$OUT/res.thr${i}.ro.txt
sleep 30
done
Im Unterschied zum Original habe ich die Laufzeit verringert, andererseits den Sysbench-Aufruf durch den Aufruf des Sysbench-Docker-Containers ersetzt und insbesondere die Anzahl der maximal laufenden Threads verringert, da sich gezeigt hatte, dass bei einer dreistelligen Anzahl von parallelen Zugriffen der MariaDB-Server keine sinnvollen Ergebnisse mehr liefert, d.h. die Zahlen brechen vollkommen ein, der Server war in dem Fall einfach überlastet. Dieses Verhalten spiegelt sich auch in der Darstellung der Ergebnisse wider.
Das Skript sorgt dafür, dass die Ergebnisse als Textdateien in ein Verzeichnis geschrieben werden – eine Datei pro Testlauf. Ein weiteres Shellskript namens „tosql.sh“ ist dafür zuständig, diese Dateien zu parsen und in eine Tabelle in der Datenbank zu schreiben. Da ich keine Tabellendefinition gefunden habe, habe ich folgende verwendet:
create table sbtest_results (
rtime int default '0' not null,
threads int default '0' not null,
tps double not null,
qps double not null,
qps_r double not null,
qps_w double not null,
qps_o double not null,
rt95 double not null,
err double not null,
reconn double not null,
addstring varchar(40) default '' not null
);
Unnötig zu erwähnen, dass hier keine Indizes gesetzt sind, was normalerweise ein No-Go wäre, aber für ein paar Hundert Zeilen und eine einmalige Auswertung sollte sogar ein Raspberry Pi eine ausreichende Leistung bringen. Der Einfachheit halber habe ich die Tabelle in der zum Test verwendeten sbtest-Datenbank angelegt.
In den Ergebnisdateien liegen die Werte jeweils in Zeilen vor, und zwar schreibt Sysbench aufgrund des Parameters --report-interval jeweils die aktuell ermittelten Daten in eine Zeile. Das „tosql.sh“-Skript verwendet zur Filterung dieser Zeilen ein weiteres, auf awk basierendes Srkript („parsem.sh„). Jedoch hatte sich seit Durchführung des Benchmarks bei Percona das Format dieser Ergebniszeilen geändert. Da ich zugegebenermaßen nicht der awk-Experte bin, habe ich für das Parsen dieser Zeilen einfach ein kleines PHP-Skript gebaut („filter.php„):
<?php
$file = $argv[1];
$addString = $argv[2];
$target = $argv[3];
$input = file($file);
$fh = fopen($target,"a+");
foreach ($input as $line) {
if (preg_match("/^\[\s(\d*)s\s\]\sthds:\s(\d*)\stps:\s(.*)\sqps:\s(.*)\s\(r\/w\/o:\s(.*)\/(.*)\/(.*)\)\slat\s\(ms,95%\):\s(.*)\serr\/s:\s(.*)\sreconn\/s:\s(.*)/", $line,$ma)) {
array_shift($ma);
$ma[] = $addString;
$x = implode($ma,';');
echo $x . "\n";
fwrite($fh,$x . "\n");
}
}
fclose($fh);
Dabei werden die Zeilen mittels regulärem Ausdruck ausgewertet und die Ergebnisse in ein CSV-File geschrieben. Die Parameter werden dem Skript übergeben: Dateiname des Sysbench-Files, Bezeichner zur Unterscheidung in der CSV-Tabelle sowie Dateiname der CSV-Datei.
Das CSV-File wird dann von folgendem tosql.sh-Skript erzeugt:
f="2.csv"
rm -f $f
for t in results/res-OLTP10t/res.*
do
echo $t
for fn in $t/res*.txt
do
res=$(basename "$t")
res=${res#res.}
php filter.php $fn $res $f
echo $t "|" $res "|" $fn
done
done
Anschließend müssen die Werte aus der CSV-Datei nur noch in die Ergebnistabelle importiert werden:
mysql -h moeckern -u sbtest -p -P 3306 -e "LOAD DATA LOCAL INFILE '2.csv' REPLACE INTO TABLE sbtest_results FIELDS TERMINATED BY ';'" --local-infile=1 sbtest
Danach können alle Auswertungen auf dieser Tabelle stattfinden. Die Original-Quelle nutzt R, um die Ergebnisdiagramme zu erzeugen – sehr versiert, sehr ambitioniert, aber da R zu den Sprachen bzw. Systemen gehört, mit denen ich mich „irgendwann mal“ beschäftigen wollte (sofern denn Zeit und/oder Motivation vorhanden gewesen wäre), habe ich mich darauf beschränkt, die Ergebnisse als Tabelle abzubilden und in ein zum Office-Paket gehöriges Tabellenkalkulationsprogramm zu überführen.
Dazu habe ich die Werte entsprechend addiert und den Durchschnitt gebildet:
select threads, round(avg(tps),2) as tpsavg, round(avg(qps),2) as qpsavg, round(avg(qps_r),2) as qps_r_avg, round(avg(qps_w),2) as qps_w_avg, round(avg(qps_o),2) as qps_o_avg, round(avg(rt95),2) as rt95_avg, addstring from sbtest_results group by threads, addstring order by addstring, threads;
Aus der daraus entstandenen Tabelle entstanden letztlich zwei Ergebnisdiagramme – dazu später mehr. Zunächst eine Betrachtung der Test-Szenarien bzw. der Parameter, die dabei variiert wurden.
Die Test-Szenarien
Der Test fand auf zwei VMs statt, die MariaDB-Datenbank wurde auf dem Host „moeckern“ eingerichtet, Sysbench wurde auf „connewitz“ in Docker-Containern betrieben. Doch wie erwähnt, die absoluten Werte sind hier weniger entscheidend und die Hardware sei daher nur am Rande erwähnt – es handelte sich um HP ProLiant DL360e G8 und HP ProLiant DL160 G8 Systeme. Insgesamt ergaben sich im Testverlauf folgende fünf Szenarien. Zur Identifikation der Szenarien innerhalb der Diagramme ist die Kennung jeweils in Klammern angegeben.
- Direkter Zugriff von Sysbench auf den MariaDB-Port 3306 kein ProxySQL (MariaDB)
- ProxySQL in einem Docker-Container (Dockerfile etc. wie im ersten Teil beschrieben), auf Host „connewitz“, Sysbench greift über den Port 6033 auf MariaDB zu, ProxySQL verbindet sich mit MariaDB (ProxySQL Remote Docker)
- ProxySQL in einem Docker-Container auf Host „connewitz“ (Dockerfile neu, Start erfolgt mit Supervisord anstatt direkt durch Starten des Binaries), Sysbench greift über ProxySQL auf MariaDB zu. (ProxySQL Supervisord)
- ProxySQL remote auf dem zweiten Host „connewitz“, installiert aus dem dpkg-Paket, Host und Ports in der proxysql.cnf angepasst, ansonsten Standard (ProxySQL remote)
- ProxySQL lokal auf dem MariaDB-Server, installiert aus der neuesten Version (zum Testzeitpunkt 1.4.3) aus dem dpkg-Paket, Parameter in der proxysql.cnf unverändert bis auf die Zugangsdaten (ProxySQL local)
Ergebnisse und Interpretation
In Diagrammen sieht dies wie folgt aus. Zunächst die Übersicht der Transactions per Second (tps), danach folgen die Queries per Second (qps). Die Antwortzeiten habe ich nicht mehr dargestellt, diese steigen mit zunehmener Anzahl der Ausführung von Sysbench-Threads an, bis die Leistungsgrenze erreicht wird.
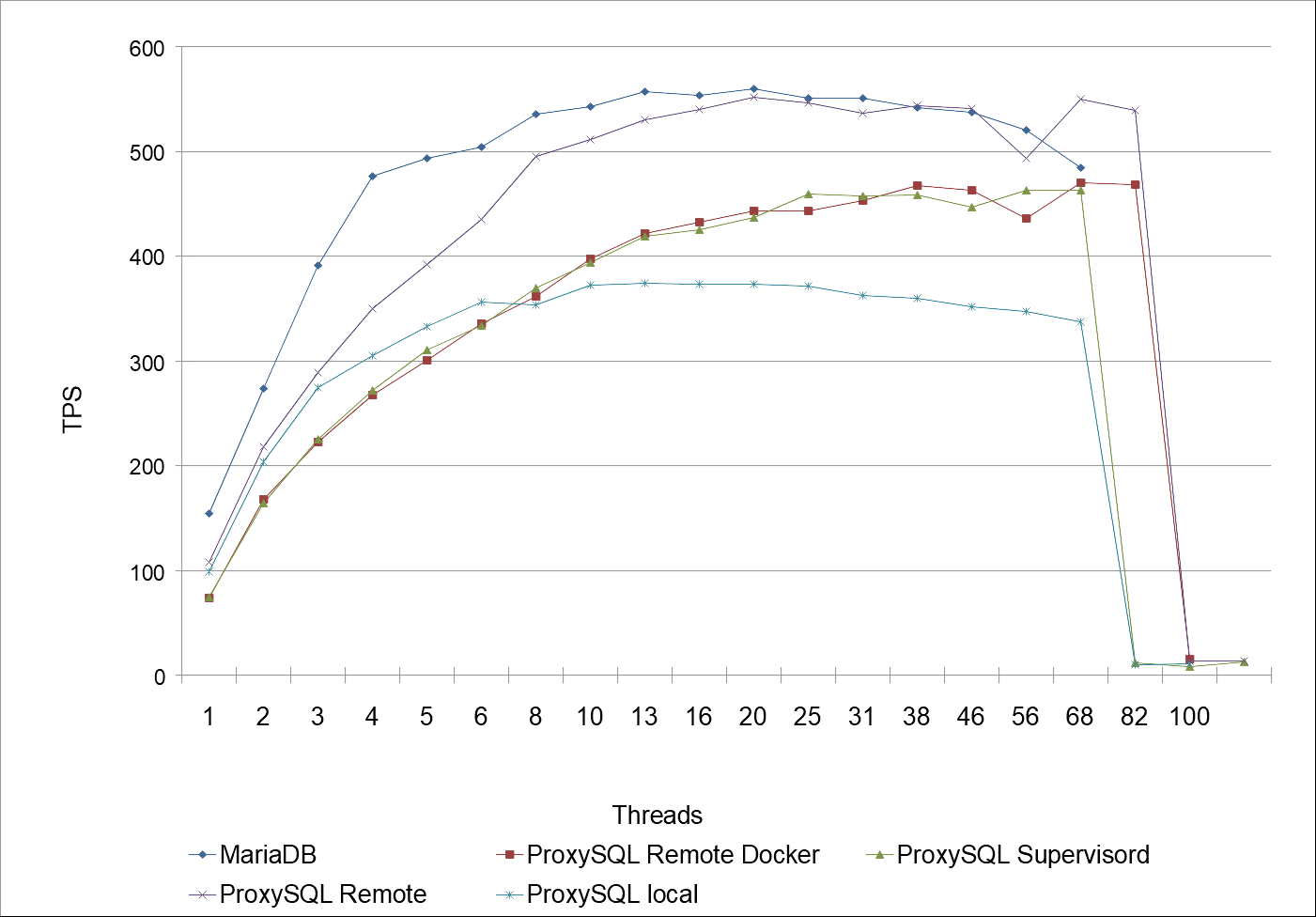
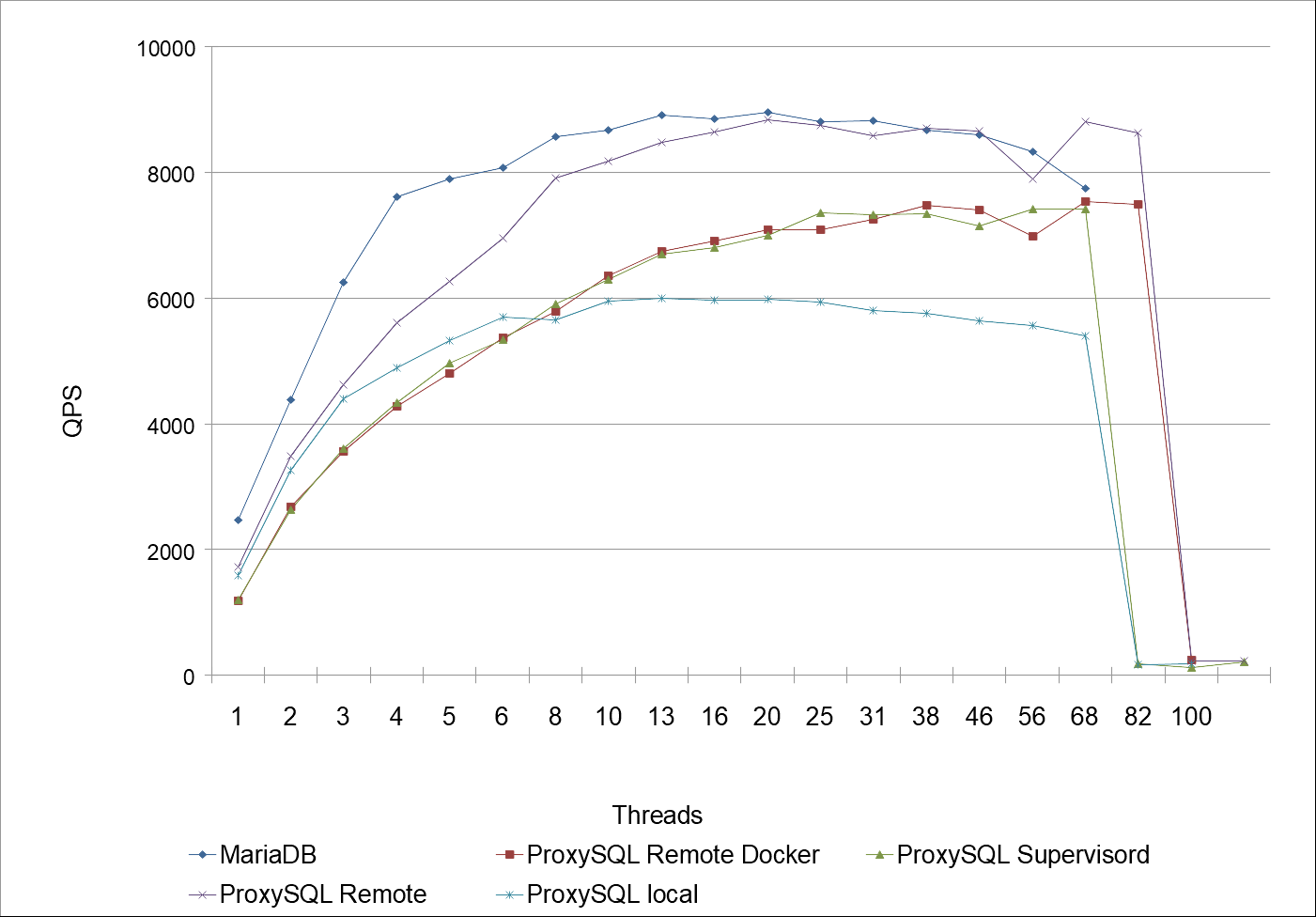
Der Grund der verschiedenen Konstellationen ist vielleicht nicht auf den ersten Blick ersichtlich. Zunächst wollte ich den Unterschied zwischen ProxySQL mit Docker, ProxySQL ohne Docker und MariaDB direkt ermitteln. Das wären somit die Fälle 1., 2. und 5.. Nun liegt es auf der Hand, dass es im ersten Fall zu Ressourcenengpässen kommt, da MariaDB und ProxySQL sich auf demselben Host befinden. Insofern ist dabei sehr verständlich, dass der Test von ProxySQL dabei die schlechtes Leistung im Vergleich liefert. Jedoch wäre dies kein Beweis gewesen, dass die Docker-Lösung besser abschneidet – schließlich lief im zweiten Fall ProxySQL mit Docker auf einem ganz anderen Host, so dass einerseits MariaDB auf „moeckern“ seine ganze Leistung zeigen konnte, und andererseits ProxySQL auf „connewitz“ erst gar nicht um die Ressourcen konkurrierte. Der Vergleich zwischen Fall Nr. 1, 2 und 5 ließ insofern kein Urteil über ProxySQL zu, genauso wenig wie über den Overhead von Docker.
Daher habe ich ProxySQL zusätzlich auf dem zweiten Host, d.h. „connewitz“ installiert, und zwar ohne Docker, d.h. aus dem dpkg-Paket, in den Diagrammen als „ProxySQL remote“ dargestellt. Daran lässt sich erkennen, dass die Ergebnisse zumindest an die reine MariaDB-Requests heran kommen, bei einer mittleren Anzahl von Threads in etwa gleich sind.
Wiederum verglichen mit der Docker-Lösung aus Fall Nr. 2 lässt sich festhalten, dass Docker bzw. vermutlich insbesondere der Web durch die einzelnen Netzwerk-Ebenen einen gewissen Overhead mit sich bringen, so ist der Betrieb von ProxySQL mit Docker zu jeder Zeit langsamer als ohne Docker. Hierzu muss ich erwähnen, dass bei den ersten, sporadischen Tests dies nicht feststellbar war, bzw. die erwähnten Konstellationen dieses Urteil zunächst nicht zuließen. Letztlich hätte es mich jedoch gewundert, wenn Docker so gar keinen Overhead mit sich bringen würde – die reine Logik spricht dagegen.
Bleibt Fall Nr. 3 – ProxySQL mit Supervisord. Eingangs hatte ich erwähnt, das Docker-Image hergestellt zu haben mit der folgenden Startsequenz für ProxySQL:
/usr/bin/proxysql --initial -f -c /etc/proxysql.cnf
Dieses Kommando startet ProxySQL im Vordergrund, liest die Konfigurationsdatei und wird im Normalbetrieb, d.h. ohne Docker, eigentlich nur beim ersten Aufruf benutzt. ProxySQL hingegen läuft normalerweise als Daemon und verwaltet sich selbst, die Konfiguration wird üblicherweise im laufenden Betrieb durch eine Verbindung eines MySQL-Clients an den speziellen Admin-Port erledigt.
Daher hat es mich interessiert, ob es einen Unterschied gibt zwischen dem Betrieb im Vordergrund, wie im ersten Image vorgestellt, oder als Daemon, d.h. ich wollte ausschließen, dass die Art und Weise, wie ProxySQL läuft, die Ergebnisse verfälschen könnte. Daher habe ich ein weiteres Docker-Image für ProxySQL erstellt, wobei ProxySQL als Daemon von Supervisord gestartet wird.
Die entsprechende Supervisord-Konfigurationsdatei supervisord.conf sieht wie folgt aus:
[supervisord] nodaemon=true [program:proxysql] command=/etc/init.d/proxysql start user = root autostart = true redirect_stderr=true stdout_logfile=/dev/stdout stdout_logfile_maxbytes=0
In der Datei entrypoint.sh wird letztlich der Supervisor-Daemon gestartet, der interessante Bereich ist folgender:
appStart () {
# start supervisord
echo "Starting supervisord..."
exec /usr/bin/supervisord -n -c /etc/supervisor/supervisord.conf
}
Wie sich jedoch in beiden Diagrammen zeigt, ist der Verlauf von ProxySQL Remote Docker und ProxySQL Supervisord nahezu identisch. Die kleinen Unterschiede dürften statistisch nicht signifikant und somit nicht relevant sein.
Insgesamt zeigt der Verlauf aller Werte, dass bei ca. 82 Threads die Lastgrenze erreicht ist – MariaDB quittiert weitere Zugriffe mit Fehlermeldungen, die Anzahl der abgearbeiteten Requests bricht ein, so dass eine Erhöhung der Threads nicht mehr empfehlenswert ist. Dies gilt für alle Konstellationen, ob mit oder ohne ProxySQL, ebenfalls wie mit oder ohne Docker.
Fazit
Ob dies positiv oder negativ ist – die Ergebnisse entsprechen letztlich den Erwartungen. So könnte man denken, dass ein Benchmark doch gar nicht nötig gewesen wäre. Einerseits mag dies zutreffen, andererseits waren die Experimente aber auch interessant und immerhin lassen sich nun Aussagen darüber treffen, wie hoch die Performance-Einbußen vom Betrieb mit Docker bzw. des Docker-Stacks in diesem konkreten Fall tatsächlich sind. Dass ich dennoch ein Fan von Docker bin und bleibe, liegt daran, dass die Vorteile je nach Einsatzzweck überwiegen. So kann ein Service mitunter einfach verteilt und hoch skaliert werden, falls die Voraussetzungen dafür gegeben sind. Falls es andererseits darum geht, eine möglichst hohe Performance auf einer Hardware zu erhalten, sind viele Abstraktions- bzw. Dateisystem-, Netzwerk- und sonstige Schichten vielleicht eine weniger gute Idee.
Nicht zuletzt hat die Beschäftigung mit den Benchmarks auch gezeigt, dass eine anfängliche Beobachtung nicht der Realität entsprechen muss. Insofern lohnt es sich immer, genauer hinzusehen und erste Ergebnisse zu hinterfragen.
 ProxySQL mit (& ohne) Docker, Teil 1 von 2")


Super Artikel! Vielen Dank für die Mühe, die du dir gemacht hast.
Ich habe vor allem bei den Schreiboperationen schlechte Erfahrungen mit Docker gemacht, was aber auch zu erwarten ist, wenn man sich mit dem Overlay-Dateisystem beschäftigt, das zwangsläufig durch die unveränderbaren Images notwendig wird. Aufgefallen ist mir das bei einem Postfix im Container, was an diverse Stellen Cache-Daten und interne Datenbanken nutzt. Durch das Copy-on-Write-Prinzip werden diese Dinge stark ausgebremst. Abhilfe schaffen hier zusätzliche Volumes für diese Dateien, auch wenn diese Daten nicht wirklich persistent sein müssen und von der Anwendung selbstständig wieder aufgebaut werden, um der Copy-on-Write-Bremse zu entgehen und viel direkter mit dem Host-System zu arbeiten. Hier hilft es, wenn ein Container eine Weile läuft mit `docker diff` die Änderungen im Container aufzuspüren.
Eine weitere Sache, die man berücksichtigen sollte, sind die tmpfs Mounts, die die meisten Distributionen für Verzeichnisse, wie /run oder sogar bereitstellen. Docker tut das nicht automatisch und ob ich in den RAM oder in einen Copy-on-Write-Layer schreibe, macht natürlich einen gravierenden Unterschied. Hier sollte man sich nicht wundern, dass der Docker Swarm Mode mit dem Compose File die Eigenschaft „tmpfs“ nicht unterstützt. Diese lässt sich aber über die „Long Syntax“ der Volumes im Compose File nutzen.
Zwei Links dazu und einen für Kernel-Anpassungen, die bei vielen Containern oder wenigen mit viel Ressourcen-Hunger notwendig werden.
Storage Driver: https://docs.docker.com/engine/userguide/storagedriver/selectadriver/
Long Syntax Volumes in Compose File: https://docs.docker.com/compose/compose-file/#long-syntax-3
Kernel Tweaking für Hosts mit vielen vieln Containern: https://blog.codeship.com/running-1000-containers-in-docker-swarm/